





Cortex-M4からの変更点
2014年9月にCortex-M4の上位後継機としてCortex-M7が発表されました。その1年以上前に新Cortex-Mが具体化されているという噂が流れ、Armユーザの中ではCortex-M5と仮の名前で呼んでいました。しかし、何の情報も入って来ず、実態は不明だったので、どんなコアが出てくるか楽しみでした。いざ、新Cortexが出てくるとM5ではなくM7になっており、みんな驚きましたが、もっと驚いたことは、性能が極端に向上されていました。パイプラインが6段になり、さらにデュアルのスーパースカラ構造です。CoreMark/MHz がM4では3.4だったものがM7では5.04に向上しています、また、DMIPS/MHzも1.25から2.14に向上しています。
バスインターフェースもCortex-Aの方式が一部取り入れられて、マイコンなのにプロセッサーのようになっています。Coretx-M4から大きく変わった点は次の通りです。
- 6段パイプラインスーパースカラ
- メモリインターフェスの改善・追加
- キャッシュ搭載
- 倍精度浮動小数点演算
一方、Cortex-M7では「ビットバンド機能」はサポートされなくなりました。
Cortex-Mシリーズの性能比較
| ベンチマーク | パフォーマンス | ||||
|---|---|---|---|---|---|
| M0 | M0+ | M3 | M4 | M7 | |
| CoreMark/MHz | 1.99 (*7) | 2.15 (*6) | 3.32 (*5) | 3.4 (*3) | 5.04 (*1) |
| DMIPS/MHz | 0.90~0.99 (*4) | 0.93~1.08 (*4) | 1.25~1.50 (*4) | 1.25~1.52 (*4) | 2.14 / 2.55 / 3.23 (*2) |
(*1)CoreMark 1.0 : IAR Embedded Workbench v7.30.1 –endian=little –cpu=Cortex-M7 -e -Ohs –use_c++_inline –no_size_constraints / Code in TCM – Data in TCM。
(*2)最初の結果は、Dhrystoneのドキュメンテーションに定められるすべての「基本原則」に準拠。2番目は、許可されたCストリング ライブラリに限らず、関数のインライン化を許可。3番目はさらに同時(「マルチファイル」)コンパイルを許可。すべてオリジナル(K&Rスタイル)のDhrystone v2.1を使用。
(*3)CoreMark 1.0 : IAR Embedded Workbench v6.50 –endian=little –cpu=Cortex-M4 -e –fpu=None -Ohs –use_c++_inline –no_size_constraints。
(*4)インライン化をオフにした状態での最小値(Dhrystoneの推奨につき)、インライン化をオンにした状態での最大値(他のプロセッサアーキテクチャ用にレポート)。Dhrystone v2.1。
(*5)IAR ANSI C/C++ Compiler V6.60.1.5097 for Arm -Ohs –no_size_constraints。
(*6)CoreMark:1.0:21.46 /Arm Cコンパイラ5.03 [ビルド24] -O3 –loop_optimization_level=2 -Otime -DMICROLIB –library_type=microlib –cpu=cortex-m0 / FPGAプラットフォーム、SRAMコード – SRAMのデータ、メモリおよびCPUクロック:10MHz。
(*7)CoreMark:1.0:19.92 /Arm Cコンパイラ5.03 [ビルド24] -O3 –loop_optimization_level=2 -Otime -DMICROLIB –library_type=microlib –cpu=cortex-m0 / FPGAプラットフォーム、SRAMコード – SRAMのデータ、メモリおよびCPUクロック:10MHz。
スーパースカラ(空間的並列処理)
スーパースカラとは、完全な並列処理を行うアーキテクチャです。例えば、複数の命令を同時にフェッチし、同時にデコードして、複数のALUで同時に演算する方式です。1つよりも2つ処理装置があったほうがパフォーマンスが高いのはあたりまえですが、ハードウエアが2倍になるので処理能力優先のマイコンでしか採用されません。ちなみに、古い技術本を紐解くと、パイプラインとあわせて次の様にまとめられていました。
- ある操作を同時に行うことができるハード(ユニット)を数個並べて、同時に動作させる最も直接的な並列処理。
- 非常に効果的。
- ハードウエアが大きくなる。
- ハードウエアと処理タイミングが合致しないとハードウエアの利用率が悪くなる。
パイプライン処理(時間的並列処理)
- 一つの操作を複数の部分操作に分解し、これらがそれぞれ独立に同時に処理できるユニットを用意し、動作させる並列処理。
- 同種の操作が連続的に行われる場合に好適(RISC向き)。
- 簡単な操作には逆効果。
- 並列度を極端に高くすることができない。
Cortex-M7の性能、エネルギー効率、安全性の観点からまとめると次のようになります。
性能とコンフィギュアビリティ
- デュアル6段パイプライン
- 強力な整数型、浮動小数点、DSP演算性能
- 柔軟なシステム/メモリ インタフェース : TCM,、AXI、 AHB
- ハーバードキャッシュ(命令キャッシュ0~64KB、データキャッシュ0~64KB)
エネルギー効率
- クロックゲーティング、WIC(ウェイクアップ割り込みコントローラ)
- Cortex-M3/M4と同じスリープモード
- 複数の電源ドメインおよび状態保持をサポート
安全性
- メモリECC(SEC-DED), MPU, MBIST, ロックステップオペレーション、フルデータトレース、安全マニュアル
- デバッグとトレース
- ETMv4 命令とオプショナルデータトレース
- シリアルワイヤーSWとJTAG
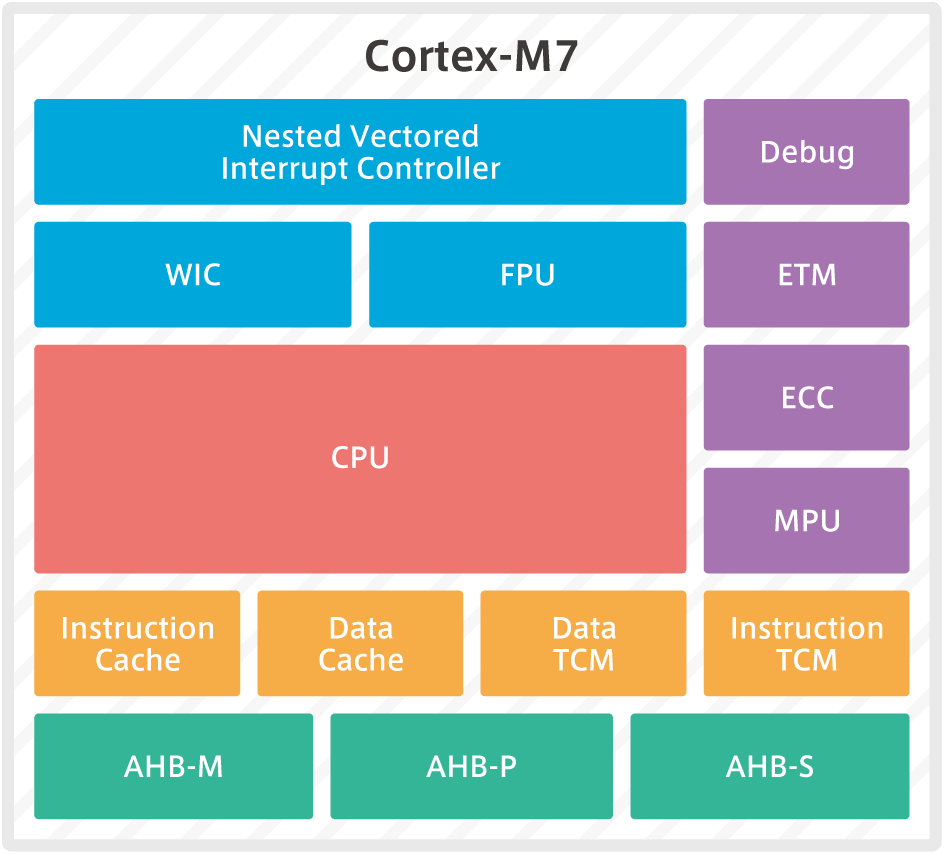
アーキテクチャの観点からまとめると次のようになります。
Arm v7E-M アーキテクチャ
- v7E-M :Cortex-M4のスーパーセット
- Thumb2(16-bit + 32bit 命令)のみ(Arm命令はサポート無し)Cortex-M4に倍精度浮動少数点命令が追加
- メモリマップドアーキテクチャ
- 単精度/倍精度浮動小数点ユニット(オプションで選択可能)
- オーバーヘッドの少ない割り込み処理のためのハードウエア(NVIC)
- 内蔵システムタイマ(SYSTICK)
追加された新機能の主なものと取り除かれた機能は次のようになります
新機能
- 浮動小数点命令の改善 - 倍精度(新命令)
- キャッシュメンテナンス
- ブレークポイントの改善
Cortex-M4からCortex-M7への互換性の問題
ビットバンディング機能無し(Cortex-M3 or M4とのコード互換性なし)
メモリマップ
メモリマップドアーキテクチャです。コア周辺( NVIC, システム制御, デバッグ…)はプライベート周辺バス(PPB)領域に割り当てられています。命令フェッチとデータアクセスの2つの異なるインターフェースを持っており、Cortex-M3/4からのI-bus、D-bus、S-busに比べると、多種多彩なインターフェースに変更されています。
インターフェース
- AXI マスター(AXIM):命令キャッシュとデータキャッシュ(オプションで選択可能)を含む
- ITCM(Instruction Tightly Coupled Memory)
- DTCM(Data Tightly Coupled Memory)
- AHB Peripheral port(AHBP)
- AHB External Peripheral Port(EPPB)
インターフェースアクセス
- アクセスのタイプ – 命令フェッチ、またはデータアクセス
- アドレスアクセス
- コントロール設定(TCMとAHBP)
- 固定されたマップが、どのインターフェースでアクセスされるかを決定
Cortex-M7の比較まとめ
| 項目 | 内容 |
|---|---|
| アーキテクチャ | Arm v7E-M |
| DSP拡張機能 | シングル サイクル16/32ビットMAC |
| シングル サイクル デュアル16ビットMAC | |
| 8/16ビットSIMD(Single Instruction Multiple data)演算 | |
| ハードウェア除算(2~12サイクル | |
| 浮動小数点ユニット | 単精度/倍精度浮動小数点ユニット(オプションで選択) |
| IEEE 754準拠 | |
| パイプライン | デュアル6段スーパースカラパイプライン(分岐予測付) |
| 性能効率 | 5.04 CoreMark/MHz(前書き参照) |
| 2.14 / 2.55 / 3.23 DMIPS/MHz(前書き参照) | |
| インタコネクト | 64ビットAMBA4 AXI、AHB周辺ポート(64MB~512MB) |
| 命令キャッシュ | 0~64KB オプショナルECC付の2ウェイアソシアティブ型 |
| データ キャッシュ | 0~64KB オプショナルECC付の4ウェイアソシアティブ型 |
| 命令TCM | 0~16MB(ECCはオプション) |
| データTC | 0~16MB(ECCはオプション) |
| メモリ保護 | サブ領域およびバックグラウンド領域を備えたオプションの8または16領域MPU |
| 割り込み | ノンマスカブル割り込み(NMI)+1~240の物理割り込み |
| 割り込み優先レベル | 8~256の優先レベル |
| ウェイクアップ割り込みコントローラ | 最大240のウェイクアップ割り込み |
| スリープモード | スリープモード |
| スリープ信号とディープスリープ信号 | |
| Armパワーマネジメントキット使用時のオプションのリテンションモード | |
| ビット操作 | ビット操作 |
| デバッグ | オプションのJTAGポートとSW(シリアルワイヤデバッグポート)。ブレークポイントは最大8つ、ウォッチポイントは最大4つ |
| トレース | オプションの命令/データトレース(ETM)、データ トレース(DWT)、インストルメンテーション トレース(ITM) |
ブロック図
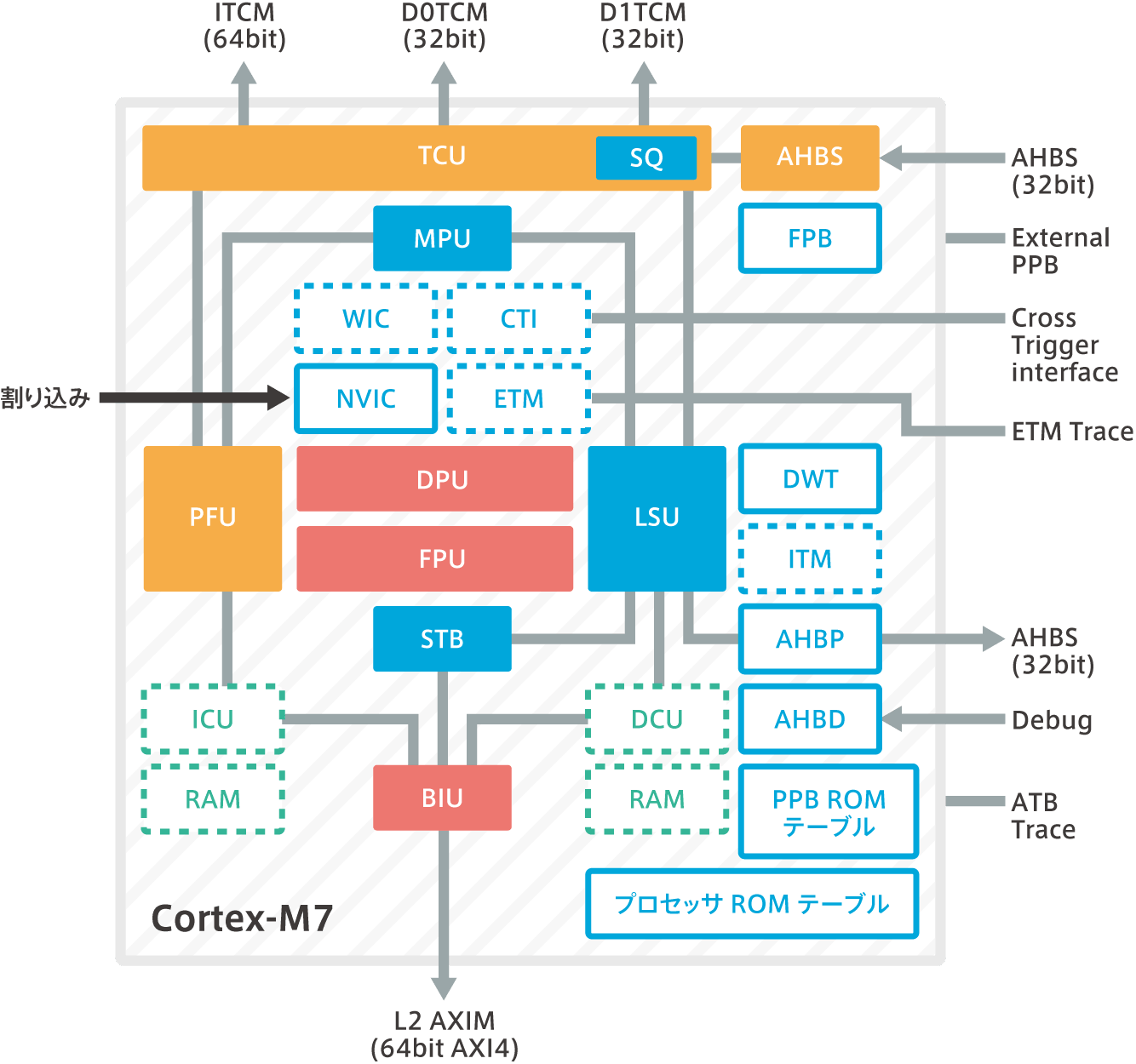
プリフェッチユニット(PFU:Prefetch Unit)
- 64bit 命令フェッチ
- 4x64bit プリフェッチキュー:DPUパイプラインから命令プリフェッチを切り離す。
- ブランチターゲットアドレスキャッシュ(BTAC):分岐予測ステートとターゲットアドレス転向を単一サイクルで実行するするための64エントリー。
- BTACが指定されない時はスタティック分岐予測。
- デコーダのダイレクト分岐の早期決定のためのフラグの転送、およびプロセッサパイプラインの最初の実行ステップ。
データプロセスユニット(DPU:Data Process Unit)
- ラージスケールデュアル発行(Issue:2ndデコード)用の並列整数レジスタファイル。6読み出しポートと4書き込みポート。
- デュアルシフタ。
- インターロックを最小化する転送ロジック。
- デュアルALU, さらにSIMD命令実行用のALU内蔵。
- シングルMACパイプラインが32x32bit + 64bit → 64bit 演算を2サイクルで実行、そして、1サイクル1MACのスループットを実現する。
- 割り算ユニット内蔵:オペランドの内容を判断して早期終了する機能付き。
ロードストアユニット(LSU:Load Store Unit)
- 64bit ロードチャネル(デュアル32ビットロードチャネル)
- 32bitのデュアル発行( Issue)は、TCMとAXIM(64bitロード幅およびデュアルの32bitロード機能)とD-キャッシュにロードする。
- シングル32ビットロードチャネルはAHBインターフェース用。
- 64bitストアチャネル1ch
- TCM用に分離されたSTB(ストアーバッファリング)とAHBPとAXIM用の QoS(Quality of Service)。
AHBD インターフェース
- AHB-Liteデバッグ(AHBD)インタフェースは、Cortex-M7プロセッサ、および完全なメモリマップへのデバッグアクセスを提供する。
AHBPインターフェース
- AHB-Lite周辺装置(AHBP)インタフェースは短いオーバーヘッド時間で、システム周辺装置に適したアクセスを提供する。
- アンアラインドメモリアクセスのサポートを提供する。
- 書き込みデータのためのバッファ、およびマルチプロセッサシステムのための排他的なアクセスを提供する。
FPU
- 単精度(SP:single precision)のために最適化された単一パイプライン。
- 1SP MAC/サイクルスループット。
- 整数パイプラインが並列実行をサポート。
- 浮動小数点コンテキストの自動スタッキング。
- 浮動小数点命令を実行する割り込みサービスルーチン(ISR)開始まで延期される。これにより、ISRに入るための待ち時間を減らし、使わないISRのために浮動小数点コンテキストのスタッキングを削除する。
- 単精度の命令(C言語Floatタイプ)データ処理オペレーション。
- 倍精度の命令データ処理オペレーションはオプション。
- 精度を上げるために掛け算と累積算を結合した命令(ヒューズMAC)。
- ハードウエアが変換、足し算、引き算、掛け算とオプションの累積、割り算、平方根をサポート。
- ハードウエアが非正規化数およびすべてのIEEE標準754-2008の丸めをサポート。
- 32の32bit 単精度レジスタまたは 16の64bit倍精度レジスタ。
タイトリーカップルドインターフェースユニット(TCU:Tightly-Coupled interface Unit)
- TCMへのシステムアクセスのための外部のECCロジックとAHBスレーブ(AHBS)インタフェースをサポート。
バスインターフェースユニット(BIU:Bus Interface Unit)
- ハイパフォーマンスL2システムをサポートする設定可能なAMBA 4 AXIインターフェース。
- 拡張されたAHB-Liteインターフェース:システム周辺機能へのオーバーヘッドの少ないインタフェース。
- オプショナルエラー訂正機能(ECC)付命令キャッシュ&データキャッシュ&コントローラ。
統合ネスト型ベクタ割り込みコントローラ(NVIC)
- NVICはコアの近くに配置されオーバーヘッドの小さい割り込み処理を行う。
- 1〜240の外部割り込み。
- 8~256の優先順位が設定可能。
- 動的に割り込み優先度を変更可能。
- 優先順位のグループ化。これにより先取している割り込みレベルか先取りされない割り込みレベルかの選択を可能。
- Cortex-M3/M4と同様に、テールチェインをサポート。これによりISR間の無駄なPUSH、POPをなくして、オーバーヘッドは最小。
ウェイクアップ割り込み制御(Wake-up Interrupt Controller:WIC)
- ウルトラローパワースリープモードからの復帰を制御。
メモリ保護ユニット(Memory Protection Unit :MPU)
- メモリの保護を行う。
- 最大16のメモリ領域とSub Region Disable(SRD)の効率的な使用を可能にする。
- デフォルトメモリマップ属性を実施するバックグランド領域を使用可能にする。
PPB ROM テーブル
- 2つのROMテーブルは、デバッガ識別を有効にし、「CoreSight」デバッグと接続することを可能にする。
Cross Trigger Interface Unit(CTI)
- CTIは、デバッグロジックとETMが互いおよび他の「CoreSight」コンポーネントに情報を伝えることを可能にする。
Embedded Trace Macro(ETM)
- ETMは、設定される時に、命令のみ、または命令とデータのトレース機能を提供。
AHBSインターフェース
- ウェイトサイクルの短いシステム周辺装置をサポートする拡張されたAHB-Liteインタフェース。
ICU
- 命令キャッシュユニットとRAM
DCU
- データキャッシュユニットとRAM
その他のメモリシステム
- 命令キャッシュとデータキャッシュとエラー訂正コード(ECC)制御。
- メモリビルドインセルフテストインタフェース(MBIST)。プロセッサーが動作中にMBISTをサポート。
デバッグとトレースコンポーネント(Debug and trace components)
- FPB(Configurable Breakpoint unit)はブレークポイントの設定を行う。
- DWT(Configurable Data Watchpoint and Trace)はウォッチポイント、データトレース、システムプロファイリングの設定を行う。
- ITMはprintf()デバッグをサポート。
- インターフェースは以下に最適
- オンチップデータをTPA(Trace Port Analyzer)に送る。SWO(Single Wire Output)モードを含む。
- デバッガはシステム内のすべてのメモリとレジスタにアクセスする。これにメモリマップドデバイス、コアがホルトとした時の内部コアレジスタも含む。そして、リセットがアサートとした時でも、デバッグコントロールレジスタにアクセスする。

こちらも是非



“もっと見る” Cortex-M7編

電力管理、コアデバッグ、浮動小数点ユニット
Cortex-M7もCortex-M3/M4と同じように低消費電力モードをサポートしています。基本はCortex-M3/M4と同じです。Cortex-M7にはWIC(ウェイクアップ割り込みコントローラ)を含むと3種類のスリープを持っていることになります。
AXI転送
AXI転送を行う際には、次に示す制限があります。バーストは、最大32バイト。バースト長さは、最大4転送。Strongly-orderedメモリまたはDeviceメモリの書き込みバーストの最大長は2転送です。Strongly-orderedメモリまたはDeviceメモリの読み出しは、常に1転送です。
キャッシュの初期化と有効化
Cortex-Aで採用されているユニフィケーションのポイント(Point of unification:PoU)と一貫性のポイント(Point of coherency :PoC)の考え方がCortex-M7でも採用されています。