





目次
Overview of the AXIM interface
About AXI Protocol
AXI (Advanced eXtensible Interface) protocol, already adopted in Cortex-R and Cortex-A, supports high-performance, high-frequency system designs, and was first introduced in the Cortex-M series by the M7.
The AXI protocol is based on the AMBA standard, but takes full advantage of its advantages to significantly improve system performance and flexibility.The best feature is the unidirectional channel architecture. The efficient use of read, write, and address/control channels results in high levels of performance and efficiency.
The AXI protocol is
- Suitable for designs with high bandwidth and short wait times.
- It can operate at high frequencies without complex bridges.
- Meet the interface requirements of various components.
- Suitable for memory controllers with long wait times during initial access.
- Provide flexibility in the implementation of the interconnection architecture.
- It encompasses the specifications and features of the existing AHB and APB interfaces (backward compatible).
The key features of the AXI protocol are
- Individual addressing/control and data phases.
- Transfer support for unaligned data is provided on a byte-by-byte basis.
- Burst-based transactions are issued only at the start address.
- Separate read/write data channels support low-cost DMA.
- Support for issuing multiple addresses.
- Support for out-of-order transactions.
The AXI protocol has an optional extension that covers signals for low power operation.The AXI protocol includes a subset of the AXI4-Lite specification, AXI4 for communication with simpler control register style interfaces within the component.
AXI Architecture
AXI’s data transfer is essentially a burst transfer. It is defined by a channel of independent transactions, such as the following
As you can see, the conventional “~ bus” has become “~ channel”. Each channel can send out information independently.There are no restrictions on the relationship between channels, such as “an address comes in, then data goes out”. Data can be transferred regardless of the timing of other channels.
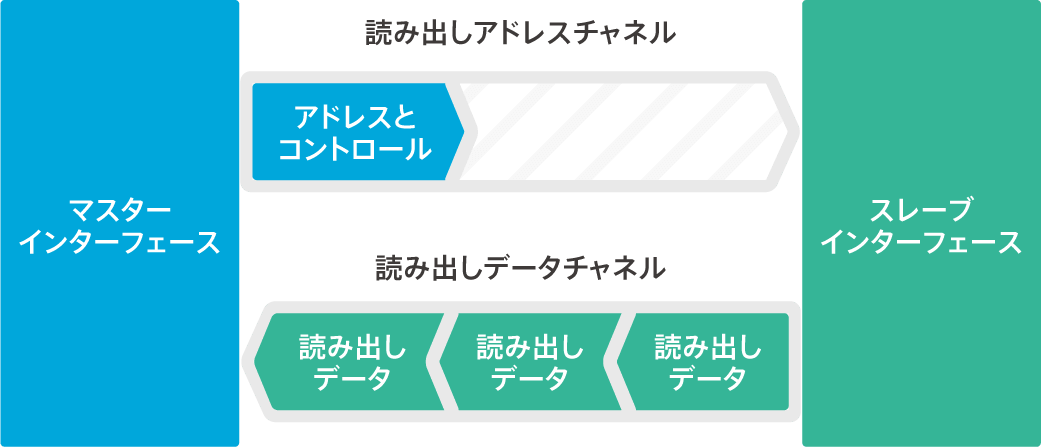
- read address
- read data
- write address
- write data
- write response
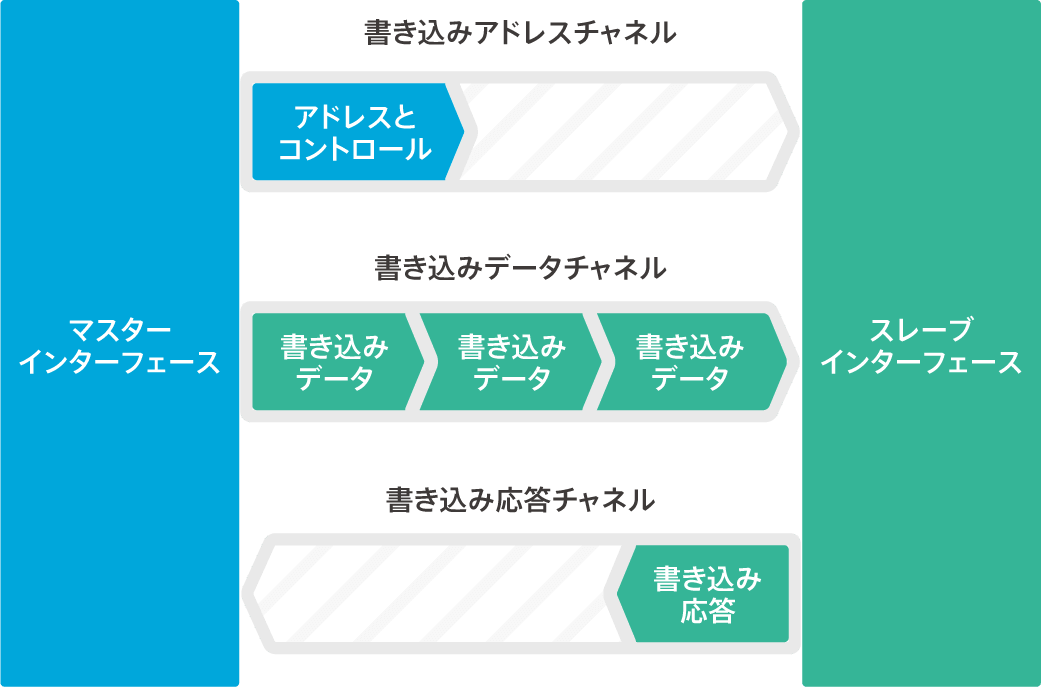
The address channel conveys control information that describes the nature of the data being transferred.
Data is transferred between the master and slave using the following
- A write data channel that transfers data from the master to the slave. In a write transaction, the slave uses the write response channel to signal the completion of the transfer to the master.
- A read data channel that transfers data from the slave to the master.
AXI protocol
- Permission to send out address information before the actual data transfer.
- Support for multiple outstandings (unprocessed) transactions.
- Support for out-of-order transactions.
Master Interface & Store Buffer
master interface
The core of the Cortex-M7 has a master function to control AXI, and the AXI interface is a system that provides high performance access to external storage devices, as mentioned earlier.
AXIM (AXI Master) supports the Arm CoreLink L2C-310 level 2 cache controller specification.L2C-310 exclusive cache configuration is not supported. When a microcontroller vendor implements an L2 cache according to this specification, it is connected to the AXI interface and controlled by AXIM.
The AXIM interface is a single, 64-bit wide interface. It is connected to an external memory system.
- 64-bit AMBA4 AXI master interface for data and instructions
- Major interfaces for addresses not covered by the TCM or AHBP
- Support for optional instruction and data caches
- Normal memory data access that cannot be cached
- Device and Strongly-ordered types of data are usually peripheral and accessible
The AXIM interface supports the AXI4 standard, as described in the Arm AMBA AXI and ACE Protocol Specification.Within the AXI standard, the AXIM interface uses a number of extended signals to indicate the inner memory attributes and the request source.
In addition, the AXIM interface can run at the same or lower frequency as the processor (in fact, some products run at a slower bus speed than the CPU, so be careful when choosing a product).
Store Buffer (STB)
The memory system has a store buffer for data retention before the data is written to the cache RAM. The store buffer is also used to hold the data before it is passed to the AXIM interface.
The store buffer holds all store data to the AXIM area of the memory map. There are four entries, each of which can contain 64 and 32 bit addresses of data.
① Store buffer behavior
The store buffer directs the write request to the next block.
- Cache controller when cache is hit: the store buffer sends a cache lookup to check that the cache has hit a particular line.If there is a hit, the store buffer will merge that data in the cache.
- AXIM interface: non-cacheable, write-through cacheable, write access is done on AXIM if the cache misses a write back with no write allocation.
For write-backs, a write allocate for missed data caches will store the data that the data cache missed. The linefill starts to use one of the two linefill buffers.When line-fill data is returned from an external memory system, the data in the store buffer is merged with the line-fill buffer and then written to the cache.
② Ejecting the store buffer
Store buffer entries will be ejected if
- When all the bytes of the entry have been written.
- When an entry is combined with a line-fill buffer.
- The entry also includes the case of a store to Device memory or Strongly-ordered memory.
- Entry is non-cacheable, write-through, and when you combine data for too long, it goes into a wait state.
The store buffer will be completely drained in the following cases.
- There was an apparent discharge requirement for
- Cash Maintenance Order.
- DMB or DSB instructions.
- An exclusive store to shared memory.
- If the store buffer is full, or about to be full, the store buffer ejects all stores of Strongly-ordered memory or Device memory before loading takes place in Strongly-ordered memory or Device memory.
L1/L2 cache
The “L” in L1/L2 stands for “Level” and is also referred to as a 1/2 order cache. L1 (first order), L2 (second order)… … and so on.
Write-back
A method of performing operations on the cache until the cache is full, and writing the data to be expelled to the main memory when a block of the cache is expelled.
Write through
When writing to the cache, the same data is written to the main memory at the same time.
line fills
A read request on the bus for the entire cache line.
For more information, see “Trivia 5” in Part 8 (updated March 2016).
AXI Limitations & AXI Concepts & AXI Benefits of Cortex-M7
The relationship between the store buffer and cache and the AXI interface is shown below.
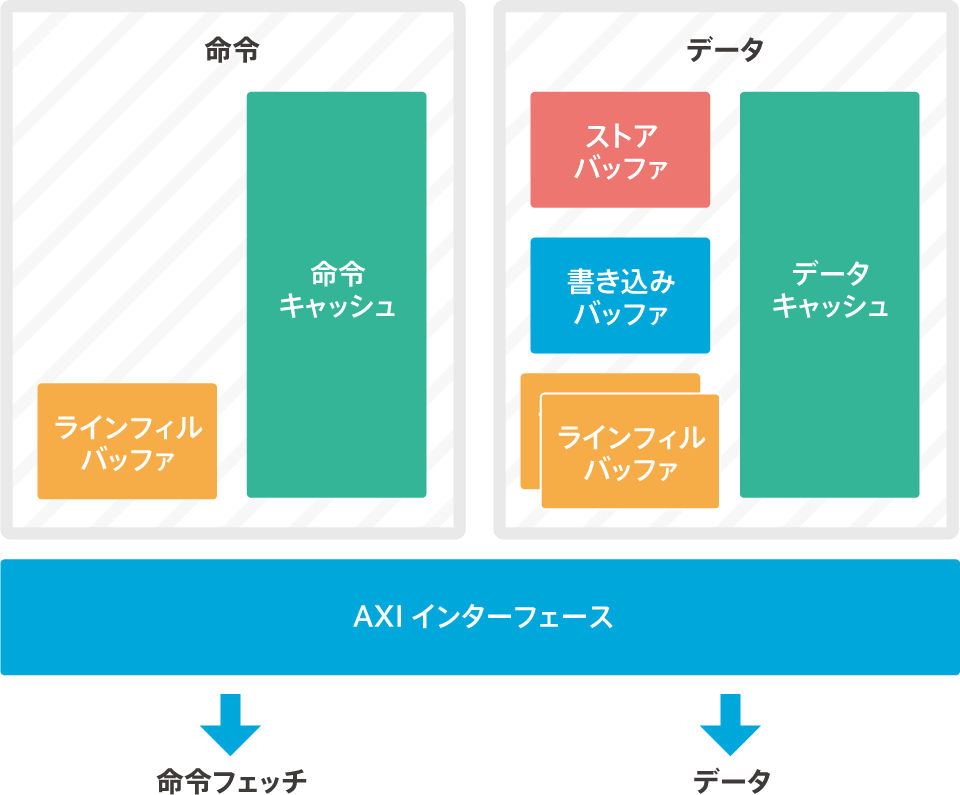
AXI transfer restrictions
The following are the main limitations of performing AXI transactions Detailed restrictions are described in the AXI Transfer (see Part 11).
- Bursts can be up to 32 bytes.
- Burst length, up to 4 transfers.
- No transactions that exceed the 32-byte boundary of memory.
- For an 8-bit 16-bit size transfer, there is always one burst transfer.
- Since it is a 64-bit AXI, the transfer size will not be larger than 64-bit.
- A transaction to Device memory and Strongly-ordered memory is always an address that is aligned with the transfer size.
- Exclusive access is always an address that is aligned for the size of the transfer.
Read
AXI Concept
AXI is a combination of the request and data phases involved.The request is independent of the corresponding data, if the bus is available during memory latency.One bus and one data for a request is equivalent. And one for the write acknowledge is optional.
If there is no functional relationship, it is also possible to misorder (e.g., instruction fetch and data fetch).
AXI’s read and write busses are separate. Reads can begin earlier than writes in the same cycle.
The five equivalent buses consist of “Read Request”, “Data Read”, “Write Request”, “Data Write” and “Write Acknowledge”.
Advantages of AXI with Cortex-M7
CM7 has several “masters” that are the “independent” equivalents. “instruction cache controllers”, “data cache controllers”, “store buffers”, etc… As a result, during the AXI transfer, Cortext-M7 is able to do the following operations For example, reading instructions from low-speed memory such as internal Flash, reading data from cacheable low-speed memory such as external memory, writing to low-speed memory to retrieve data cache lines such as external SDRAM, and reading 0WS (zero-weight) to cacheable memory. Or writing.

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …