





目次
Development of the Arm Architecture
The Arm architecture was designed and developed by Acorn Computers Limited in the U.K. between 1983 and 1985, and in November 1990 an engineer who spun out of Acorn Computers designed and developed the Arm architecture. Advanced RISC Machines Limited is founded. The Arm6 was the first commercial RISC microprocessor to be developed. The processor was named after Advanced RISC Machines.
Arm7TDMI, a redesign of Arm7, the implementation of Thumb instructions (16-bit instructions), grew into a processor that combines low power consumption and high code efficiency. To solidity. Since then, the Arm7 has been improved and evolved into the Arm9, Arm10, and Arm11.
Among them, the Arm9 processor has been widely popularized, and the total number of shipments has exceeded 5 billion units. There are now more than 250 silicon licensees and more than 100 licensees of the Arm926EJ-S processor. After Arm11, a new series of development is underway as a new series development, divided into Cortex-A / Cortex-R / Cortex-M. The latest architecture is Armv8-A/ Armv8-R (64-bit), which has been released.
Arm Processor Feature
The Arm processor is a 32-bit Reduced Instruction Set Computer (RISC) with low power consumption features. It offers a good balance between instruction density and low power consumption, and also incorporates the advantages of a CISC (Complex Instruction Set Computer) processor. For example, it has the following features
- Thumb2 instruction set uses a mixed instruction set of 16-bit and 32-bit instructions
- Constant Shift Instructions/Rotated Operand Instructions
- Conditional execution instruction (allows conditional execution without using branch instructions)
- Comparatively rich addressing modes
- Unaligned memory access support
Accesses other than 32-bit address boundaries in the case of 32-bit data or 16-bit address boundaries in the case of 16-bit data are called unaligned memory accesses. Accesses for 32-bit data and 16-bit data from odd-numbered addresses are unaligned memory accesses.
Initially, I was developing embedded systems using other processors, not Arm, but around 2002, I was first introduced to Arm processors. My first exposure to the Arm processor was when I started programming on the Arm7TDMI in the evaluation kit. Specifically, the following points set it apart from other processors
- The stack pointer link register program counter is not independent.
- Automatically switches registers depending on processor mode.
- When an exception occurs, the correction of the return address is necessary for the cause of the exception.
- No return instruction exists.
- When the SWI instruction (software interrupt) is used, there is no register where the software interrupt number can be found.
- The processor control registers are not located in memory space (4 Gbytes). It is possible to use the whole memory space effectively because it uses dedicated instructions to access it.
Since the cause of the exception is different depending on the pipeline stage, the correction value of the return address is also different.
The initialization and interrupt processing required assembly language, but it was simple and easy to use, and I remember debugging it using an in-circuit emulator while looking at the instruction table and sample programs to get a better understanding of how it worked. Later, I tried to touch Arm 9/Arm 11, but I had a very hard time understanding how to initialize the processor and how it worked, and I had a hard time getting it to work properly. I hope that the introductory Cortex-A article starting in this issue will provide an opportunity for many engineers to learn Arm processors without any unnecessary effort.
History of the Architecture
This section describes the history of Arm processors since v4/v4T, when they began to be used for embedded devices; non-privileged software created in the Armv4T architecture can be used in Armv7 processors as well, as the Arm-A8 has 13 stages in the pipeline and the Cortex-A9 has 9 to 12 stages in the pipeline. However, the Cortex-A8 has 13 pipeline stages, and the Cortex-A9 has 9 to 12 stages, and even though the architecture is v7-A, the internal structure is different, so building the source code to match the Armv7 processor you are using is the best way to get the best code and performance It is possible. Next, let’s discuss the history of the architecture.

From the v4 to v6 generation of the architecture, the architecture can be divided into application processors and embedded processors. The application processor is equipped with a memory management unit (MMU) and is able to utilize virtual memory. The embedded processor is equipped with a memory protection unit (MPU) and can provide memory protection even in systems using a real-time OS. For example, if you are using the Arm926EJ-S, it is architecture v5.
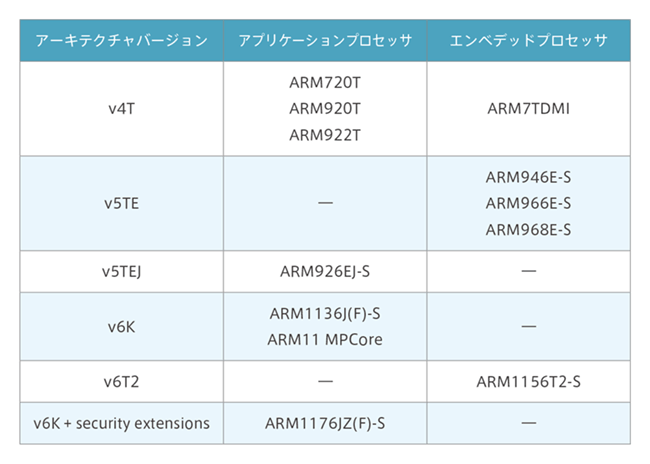
Starting from architecture v7, the number of microcontroller profiles has increased to 3. The Cortex series is not all architecture v7, Cortex-M0/M0+/M1 will be architecture v6 instead.
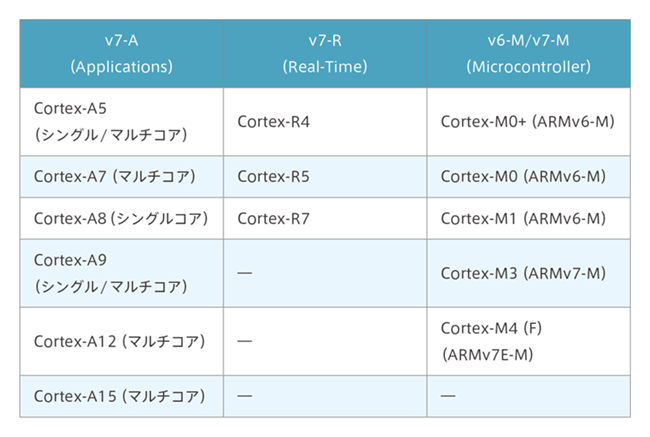
About the Cortex series
Cortex includes Cortex-A, Cortex-R and Cortex-M, where A stands for Application, R for Real-time and M for Microcontroller. As you may have noticed by now, the name is “Arm”. This time, I will explain the features of Cortex-A. I will briefly explain the features of the three series.
Cortex-A Series
The architecture of Cortex-A is Armv7-A. A typical series is the Cortex-A9, which can achieve a performance of 2.5 DMIPS/MHz. Operating frequencies range from 600MHz to 1GHz and can be used as a single-core processor or a 1-4 core multi-core synthesizable processor, allowing applications to run on advanced operating systems such as Linux/Android. The Cortex-A9, in particular, is available in a number of products and has been used in products with real-time operating systems.
Cortex-R Series
The architecture of Cortex-R is Armv7-R. A typical series is the Cortex-R4, which can achieve a performance of 1.66 DMIPS/MHz. Although the performance is likely to be lower than the Cortex-A series, the use of tightly coupled memory (TCM), which is locally connected to the processor to ensure real-time, allows programs to run quickly. To create a high-reliability system, a memory protection unit (MPU) is included to provide additional security through the use of memory protection and dual-core lockstep features. Although limited in availability as a device, it has been adopted in areas with stringent demands for safety and real-time performance.
Cortex-M series
The architecture of Cortex-M is Armv7-M. A typical series is the Cortex-M3, which can achieve performance between 1.25 and 1.50 DMIPS/MHz, which is considered low when compared to the Cortex-A and Cortex-R series, but is high enough for a microcontroller. The nested vector interrupt controller provides a flexible interrupt response, which is important in real-time control, for ease of use. A memory protection unit (MPU) can also be integrated to create a highly reliable system.
For more information, see the Cortex-M chapter.
合わせて読みたい

About the Cortex-A Family
The Cortex-A family of processors consists of the following lineups
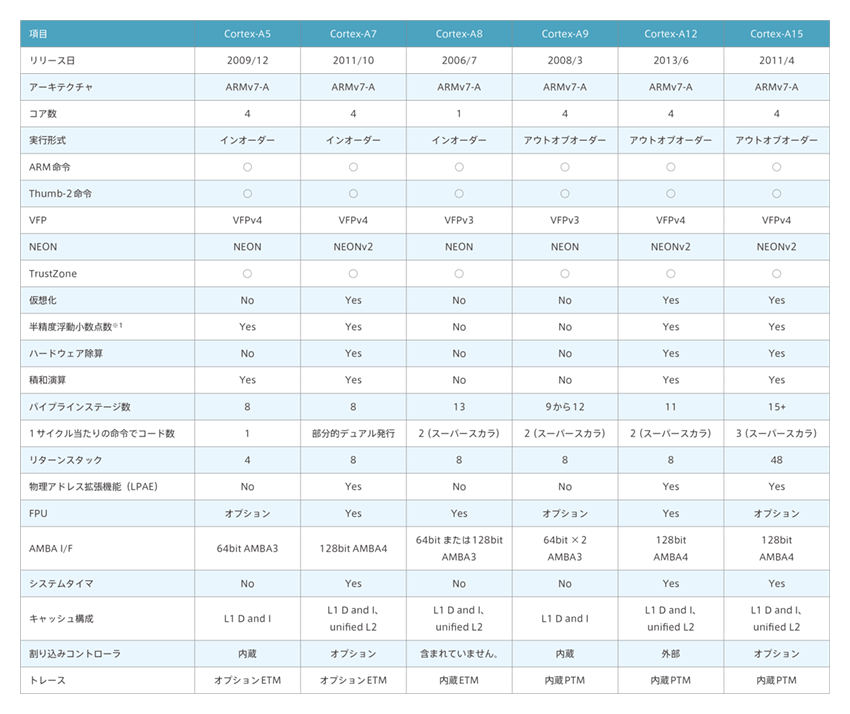
(*1) What is a half-precision floating-point number? Half-Precision Floating-Point Numbers: a type of floating-point number expressed in the floating-point system in a 16-bit format. It has been standardized in IEEE 754-2008.
Features and functions of the Cortex-A series
It is an application processor that supports applications running on a high-performance OS such as Android/Linux. This section describes its features.
Thumb-2 instruction set
An instruction set added in Armv6T2 that extends the 16-bit Thumb instruction set to support 32-bit instructions; the combination of the 16/32-bit Thumb instruction set achieves nearly identical code density to the Thumb instruction set, but with the 32-bit instruction set’s Performance is possible. Unlike previous Arm processors, the Cortex-A(*2) series also includes hardware division. For instructions, please refer to Arm and Thumb-2 Instruction Set Quick Reference Card (English) v4.0.
Register Set
There are 16 32-bit wide registers (r0-r15) and some of the registers are automatically switched according to the processor mode.
Response to out-of-order execution
Programs (not high-level languages such as C/C++ or other high-level languages, but at the machine language instruction level as a result of compilation) generally execute instructions in an orderly fashion. It is a technique that aims to increase the efficiency of computer instruction execution. When a program is executed, it is executed in the order of instructions, but some instructions are executed in a different order, which is one of the optimization techniques that increases the possibility of concurrent execution of multiple instructions.
Load Store Architecture
The Arm processor is a load-store architecture. When performing an operation (numerical and logical operations), the operation is performed between registers. It is not possible to perform the operation between memories.
Hardening unaligned memory access
In the case of RISC processor, structure members are placed at natural boundaries (*3). General RISC microcontrollers only have a natural boundary access function, so access is made in byte units and logical operations (AND, OR, and shift operations) are used to convert the data into the corresponding data. As a result, the number of instructions and data access bus cycles increases, which slows down execution speed, while in the case of the Arm processor, the increase in instruction count can be reduced because the hardware executes unaligned access. (Bus cycles increase the size of the accesses compared to natural boundary placement, so performance is reduced.)
4 GByte of memory space can be used effectively
Endian support (*5)Cortex-A series instructions are fixed at little-endian; Cortex-R series instructions can select endianness at the system level; Cortex-A series data accesses support big-endian and little-endianness. They can be controlled by bits in the Current Program Status Register (CPSR).
CPSR.E: Because it controls the endianness of load/store instructions, endian conversion can be performed dynamically in the program. It has the instructions (REV, REV16 and REVSH) that can perform endian conversion. The endian at the time of exception can be selected, and CP15: SCTLR (System Control Register, C1) can be controlled by EE bits.
MMU (Memory Management Unit)
The MMU performs virtual address translation through a hardware page table walk. When converting a virtual address to a physical address, the MMU is used to perform the address translation; the MMU automatically refers to the TLB and performs the virtual to physical address translation. The page size can be selected from 4KB, 64KB, 1MB or 16MB. With the software TLB management method (detection of TLB miss exceptions), the entry table must be replaced by software, but in the case of the Arm processor, the hardware replaces the page table.
Cortex MP Core Processor
Multi-core (up to four cores) systems can be configured for Symmetric Multi-Processing (SMP) and Asymmetric Multiprocessing (AMP). It has a smooth control unit that manages L1 cache coherency and management during SMP operation.
Split Prediction Function
The Cortex-A series has a deep pipeline stage and includes a dynamic branch prediction function/branch target address cache (BTAC)/return stack to reduce the penalty due to branching instructions.
Performance Monitoring Unit and Tracing
To measure program performance, Arm processors have been using Embedded Trace Macrocell (ETM) or Program Trace Macrocell (PTM). However, as processors become more powerful, it is necessary to properly understand the sources of performance variability (e.g., cache hits and misses). A performance monitor unit is included as a function to monitor the internal operation of the processor core.
Jazelle
Jazelle-DBX (direct bytecode execution) allows a subset of Java bytecode to be executed directly in hardware.
big.LITTLE processing
This technology is designed to extend the battery life of mobile devices. It combines a relatively large, high-performance CPU core (big) with a small, low-power consumption CPU core (LITTLE) to save power. High-load processes are executed on the high performance CPU core and low load processes are executed on the low power consumption CPU core.
(*2) Cortex-A7/A12/A15 are capable of executing hardware division instructions.
(*3) A natural boundary means that 32-bit data is placed on a 32-bit boundary and 16-bit data is placed on a 16-bit boundary. Placing the data on a natural boundary makes it possible to improve data access efficiency.
(*4) The Cortex-M series is located in memory space.
(*5) Access to the internal area (for Cortex-A9 MPCore, private memory area) is fixed at little endian. Note that there is an access size limit in the private memory area.
Data size used by Arm processors
The data that Arm processors work with is unified regardless of architecture.
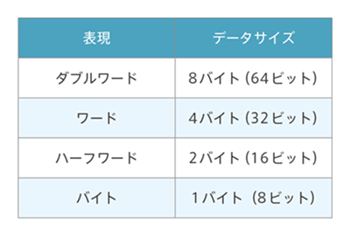
Data size handled by general-purpose registers
The data size that the Arm processor registers (r0 to r15) can handle is as follows. The register width is 32 bits, so two registers are used to handle double words (8 bytes).
The Cortex-A series includes a floating point unit (FPU) and extended SIMD(*6) extension (NOEN), FPU/NEON is standard in the Armv7-A architecture.
(*6) SIMD (single instruction multiple data) refers to a form of computer parallelization in which multiple data operations are performed with a single instruction. It is also known as packed operation or vector operation. Performing a single data operation is called a scalar operation.
Data size handled by Arm floating point architecture (VFP)
Arm Floating-Point Architecture (VFP) provides hardware support for half-, single- and double-precision floating-point arithmetic and is fully compliant with IEEE 754(*7) with support for software libraries. VFPv3 implements 32 double-word (64-bit) registers; the Cortex-A9 is VFPv3-D16, consisting of 16 double-word registers, and VFPv4 is available on the Cortex-A5/A7/A15. VFP (Vector Floating-point Architecture) supported vector mode, but the Armv7-A architecture allows for vector operations in NEON.
(*7) IEEE754 (IEEE Floating-Point Arithmetic Standard) is the most widely adopted standard for the calculation of floating-point numbers.
Data size used by NEON
The VFP is a single instruction that can perform 8/16/32/64-bit integer arithmetic and 32-bit (single-precision) floating-point arithmetic suitable for multimedia processing. The registers can be used as 32 64-bits wide registers (128-bits wide, 16 registers), and the NEON register is shared with the VFP register, so it can be accessed by the 32 64-bit registers of the VFP and the NEON.
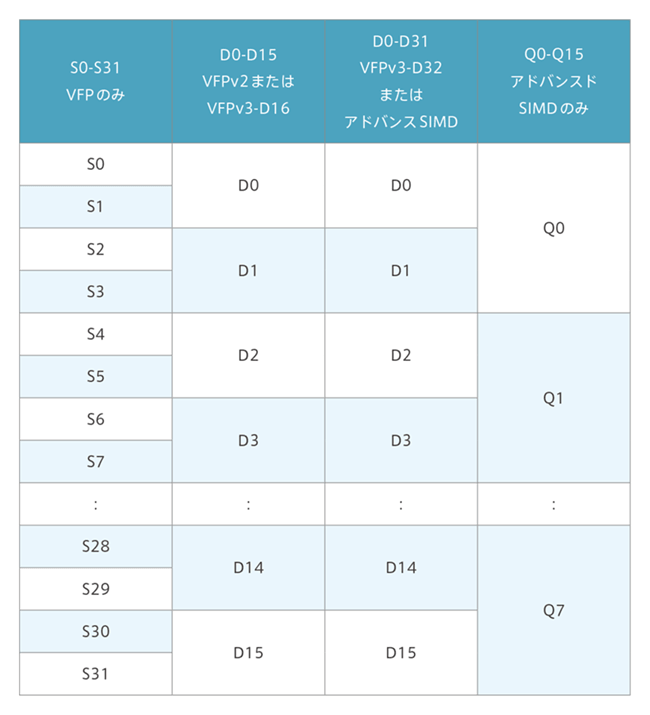
Register Mapping of NEON and VFP
Endian as defined by Arm
Arm processors are based on little endianness; Arm processors define three types of endianness. The common little endian is LE, the big endian is BE-8, and the architecture v7 does not support BE-32.
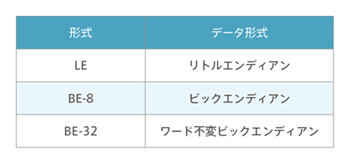
Endian format / Data format

LE (little endian) format

BE-8 (big endian) format
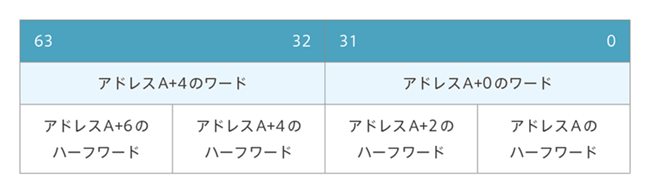
BE-32 (word-invariant big endian) format
How to read the processor manual
There is a trick to reading the manual when using Arm processors.
(1) Architecture: Armv7-A/R is the basis of the Arm processor
- Arm Architecture Reference Manual “Armv7-A and Armv7-R Edition”
(2) Technical Reference Manual for your Arm processor
If you are using the Cortex-A9, you must read the following four manuals
- Cortex-A9 Technical Reference Manual
- Cortex-A9 MP Core Technical Reference Manual
- Cortex-A9 NEON Media Processing Engine Technical Reference Manual
- Cortex-A9 Floating Point Unit Technical Reference Manual
(3) Device vendor’s supply manual to be used
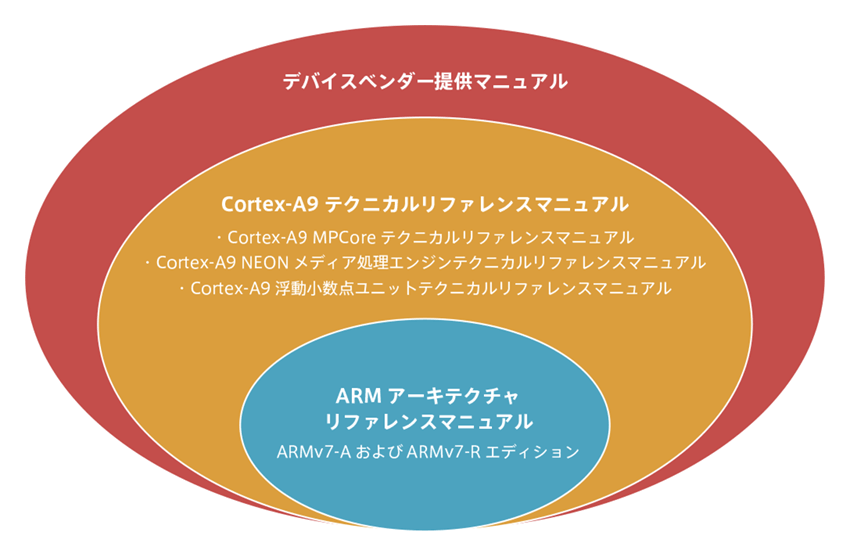
Learning the above order will help you understand the Cortex-A processor you are using. However, reading such a large amount of manuals can be difficult.
The Cortex-A Series Programmer’s Guide (Version 1.0) is the best way to learn how to program the Cortex-A Series efficiently.
[Japanese] “Cortex-A Series Programmer’s Guide
[English Version] “Cortex-A Series Programmer’s Guide Version: 4.0”

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …