





Pipeline Overview
The pipeline will be explained in detail in Volumes 4 and 5, but since it is a major change from Cortex-M3/4, I will briefly explain it first.
Dual 6-stage super scalar pipelines
It’s a dual superscara, so there are two ALU.It fetches the code in 64bit, decodes two instructions simultaneously, and issues the decoded results to two ALU.And run it simultaneously. Therefore, as mentioned above, both CoreMark and DMIPS have almost twice the computing power of Cortex-M4.Unfortunately, due to the relationship between two instructions decoded at the same time, it may not be able to execute at the same time, so it doesn’t completely double, but it still has high performance.(Typically, dual superscalars are said to perform 1.6 times better than a single pipeline.)
Instruction issuance pipeline (fetch to decode processing)
It’s a three-stage pipeline process from fetching to decoding to discriminating instructions.The decoding process is in two stages, the first decode is called Decode, the second decode is called Issue.Issue the decoded instruction to the execution pipeline at a later stage.
execution pipeline
Logical operations (including shifts) and arithmetic operations are performed by the ALU, but other operations are performed by a dedicated pipeline and are executed by other hardware.They are allocated to each pipeline according to the type of instruction that is decoded.For load/store execution, the load/store pipeline is the load/store pipeline; for complex multiplication and summation operations, the Mac pipeline; and for floating-point operations, the floating-point arithmetic pipeline.These hardware do the parallel processing.
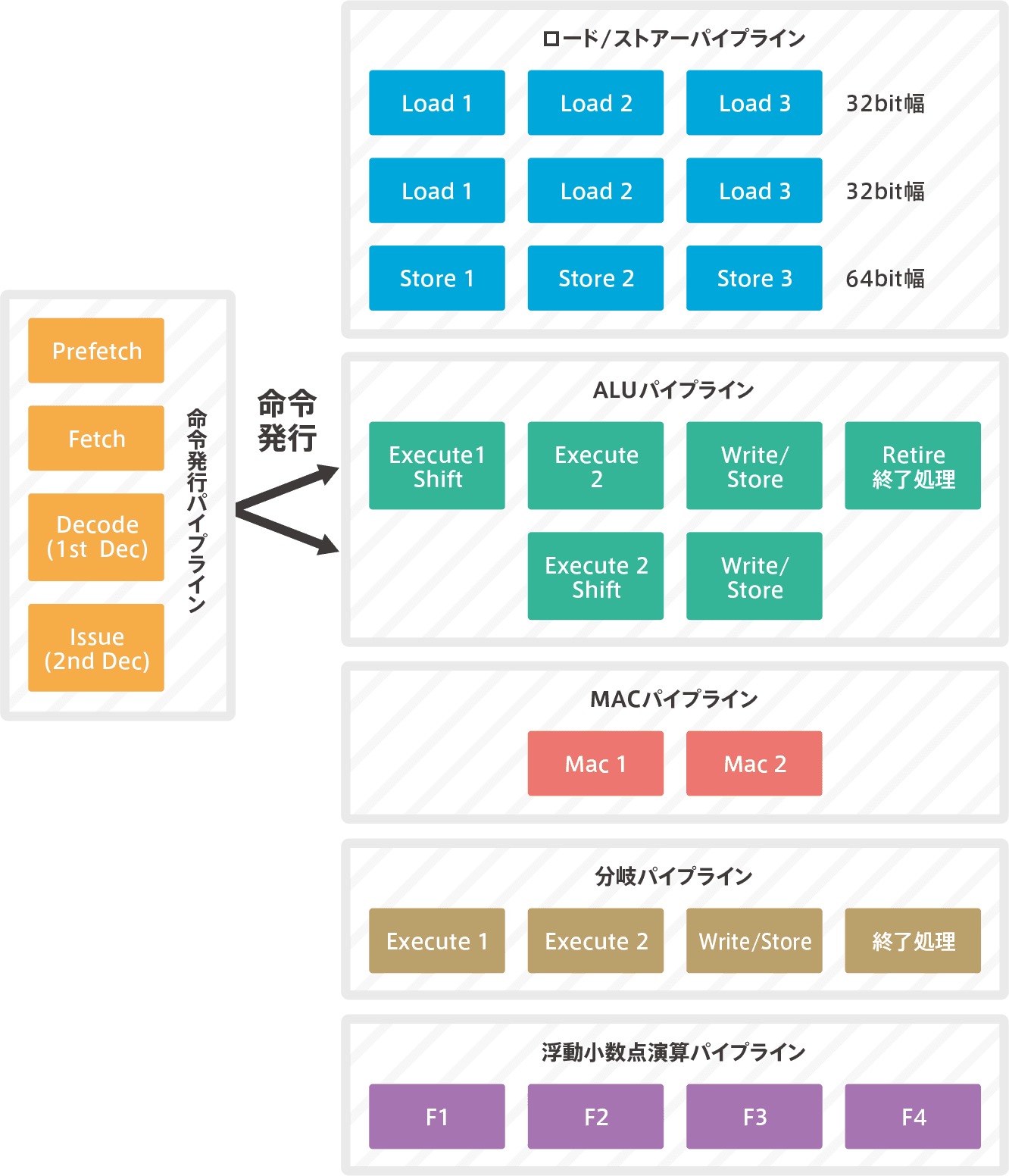
【Cortex-M7 pipeline】
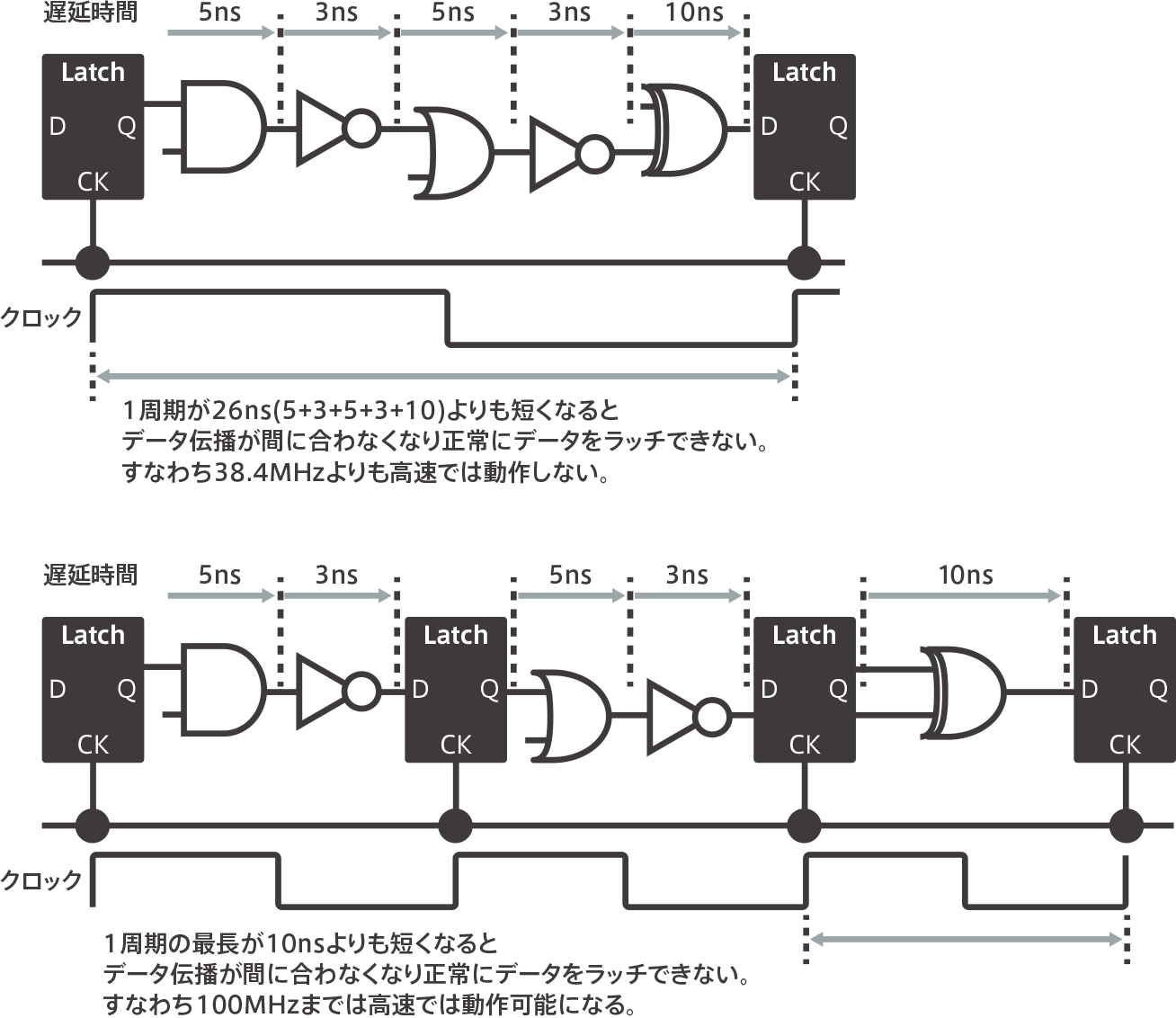
Why increasing the number of pipeline stages can lead to faster processing
The Cortex-M3/M4 had a three-stage pipeline, but the Cortex-M7 has increased that to six stages.This is a device to improve performance by increasing the operating frequency.So, let’s briefly explain why increasing the number of stages in the pipeline can lead to faster processing.One clock per pipeline stage is processed.The above figure below shows an example of a logic circuit that is processed by one clock. If you add up all the delay times for each logic gate, you get 26ns.Therefore, a clock of 38.4MHz or higher will not be sufficient for processing.Inevitably, the maximum operating frequency of this microcontroller is 38.4 MHz.However, in the figure below, the same process has been split into three stages. It is a mock-up of the so-called three-stage Papui line.The greatest delay time is 10ns at the most. Therefore, it can run up to a 100MHz clock.Pipeline processing is effectively one clock and one instruction, even if the number of stages is increased.Therefore, increasing the number of stages makes faster processing possible.(See Cortex-M, Part 10)
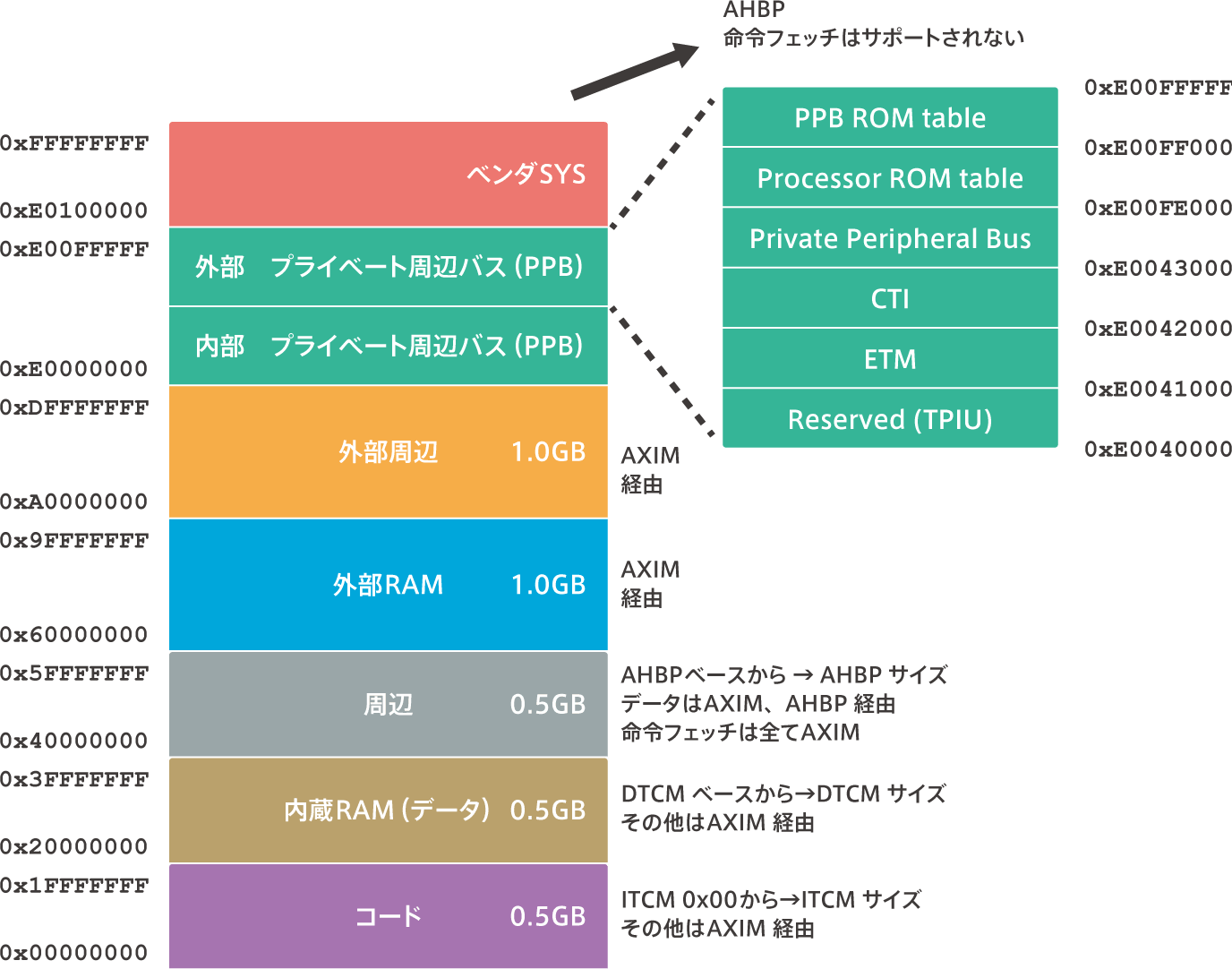
memory map
Overview of the memory map

【Cortex-M7 bus interface】
The memory map of the Cortex-M7 is the same as that of the Cortex-M3/M4.However, whereas the Cortex-M3/M4 had only I-Bus, D-Bus, and S-bus interfaces, the Cortex-M7 has AXIM, ITCM, DTCM, AHBP, and EPPB bus interfaces.In the Cortex-M7, each area of the memory map has a different bus interface that is connected to it.For example, the bus interface is different between fetching instructions from the built-in Flash provided in the code area and fetching instructions stored in the external memory.The former is via ITCM or AXIM and the latter is only via AXIM.(The name of the bus is AXI, but the hardware that is the master and controls AXI is called AXIM, where M is M for Master.)
code area
The internal memory (Flash, RAM) that stores the instruction code is usually connected to this area.The bus interface is connected to AXIM and ITCM, where I stands for Instruction.It starts at the 0x00000000 address and exists for the size of the actual internal memory. The maximum is 0.5GB.
Built-in RAM (data) area
The internal memory (Flash, RAM) that stores the data is usually connected to this area.The bus interface is connected to AXIM and DTCM, where D stands for data.It starts at 0x20000000 and exists only for the size of the actual built-in memory. The maximum is 0.5GB.
edge area memory map
It is an area where registers of peripheral functions such as UART, timer, USB, Ethernet, etc. are mapped.The bus interface is connected to AXIM and AHBP.Data access is via AXIM or AHBP, but instruction fetching is only via AXIM.It starts at 0x40000000 and actually exists as much as the size of the register area of the built-in peripheral functions. The maximum is 0.5GB.
External RAM area
This is the area for external RAM (memory). Instruction fetching and data access is done via AXIM.It starts at 0x60000000 and exists only for the size of the implemented external memory area. The maximum is 1.0 GB.
external peripheral area
This area is used for external peripheral functions. Instruction fetching and data access is done via AXIM.It starts at 0xA0000000 and exists for the size of the implemented external peripheral functional area. The maximum is 1.0 GB.
private peripheral bus area
This is the area where the registers for external peripheral functions of the processor are placed.Data access to the registers here is via EPPB. This area is Execute Never (XN).This means “instructional fetching is forbidden”.It starts at 0xE0000000 and exists for the size of the implemented register area.
- The internal PPB provides access to the following features
- ● ITM(Instrumentation Trace Macrocell)
- ● DWT(Data Watchpoint and Trace)
- ● FPB(Breakpoint unit)
- ● System Control Space (SCS), Instruction and Data Caches and Nested Vectored Interrupt Controller (NVIC), System Timer (Systick)
- ● Processor and PPB ROM table
- The external PPB provides access to the following functions
- ● ETM(Embedded Trace Macrocell)
- ● CTI(Cross Trigger Interface)
- ● CoreSight debug and trace components on external systems
Vendor SYS area
It is a system segment for vendor system peripheral equipment.Data access is done via the AHBP interface.This area is an XN and instruction fetching is prohibited, starting at 0xE0100000.
Handling of Unaligned Access on 32bit Data Boundaries
The Cortex-M7 processor supports unaligned access (see Cortex-M Part 8).All accesses are apparently run in a single cycle.Internally, however, they are converted into two or more aligned accesses that are executed.Therefore, it is slower than aligned access.In addition, unaligned access is not supported in some memory areas (e.g., PPB).That’s why Arm recommends using aligned access.If an unexpected unaligned access occurs, you can find out by checking “UN ALIGN_TRP-bit” in the Configuration Control Register.

Also, unaligned access can only be used for the following instructions.
- LDR, LDRT
- LDRH, LDRHT
- LDRSH, LDRSHT
- STR, STRT
- STRH, STRHT
This other load/store instruction raises an exception (UsageFault).It’s a useful feature, but you need to be careful when using it.

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …