





目次
Armアーキテクチャの開発経緯
Armアーキテクチャは消費電力を抑える特徴を持った、モバイル機器において多く採用されているプロセッサです。1983年から1985年に英国Acorn Computers Limitedにより設計・開発され、1990年11月に同社をスピンアウトしたエンジニアが、Advanced RISC Machines Limitedを設立。商用RISCマイクロプロセッサとして最初に開発されたのがArm6です。プロセッサの名前は、Advanced RISC Machinesから名付けられたものです。
携帯電話が普及期に入り、Arm7を再設計したArm7TDMIは、Thumb命令(16ビット命令)を実装することで、低消費電力と高いコード効率を両立させるプロセッサに成長。Arm7TDMIは、大量生産される機器に採用され、ArmプロセッサとArm社の地位を確固たるものへ。その後、Arm7は改良を重ね、Arm9、Arm10、Arm11へと進化しています。
なかでもArm9プロセッサは広く普及を遂げ、累積出荷数が50億個を突破。シリコンライセンシは250社以上、Arm926EJ-Sプロセッサのライセンシは100社以上に。現在も幅広いアプリケーションに継続的に採用されています。Arm11以降は、新しいシリーズ展開として、Cortex-A/Cortex-R/Cortex-Mに分かれて開発が進められています。最新のアーキテクチャとしては、Armv8-A/ Armv8-R(64ビット)がリリースされています。
Armプロセッサの特徴
Armプロセッサは、32ビットRISC(Reduced Instruction Set Computer:縮小命令セットコンピュータプロセッサ)で、消費電力を抑える特徴を持っています。命令密度と低消費電力を高度にバランスさせ、CISC(Complex Instruction Set Computer:複合命令セットコンピュータ)プロセッサの利点も取り入れています。例えば、以下の特徴があげられます。
- Thumb2命令セットは、16ビット命令と32ビット命令の混在命令セットを使用
- 定数シフト命令/ローテート付きオペランド命令
- 条件実行命令(分岐命令を使用せず、条件実行が可能)
- 比較的豊富なアドレッシングモード
- 非整列メモリアクセスの対応
32ビットデータの場合の32ビットアドレス境界以外のアクセスや16ビットデータの場合の16ビットアドレス境界以外のアクセスを非整列メモリアクセスと言います。奇数番地からの32ビットデータや16ビットデータのアクセスは非整列メモリアクセスです。
筆者とArmプロセッサとの出会い
当初はArmではない、他のプロセッサを使用して組み込みシステムの開発をしていましたが、2002年頃に、Armプロセッサを初めて知りました。最初に触れたのは、評価キットに搭載されているArm7TDMIにてプログラミングを始めた時です。Armプロセッサで驚いたのはアーキテクチャの違いでした。具体的には、次のポイントが他のプロセッサと異なる点です。
- スタックポインタ・リンクレジスタ・プログラムカウンタが独立していない。
- プロセッサモードに応じて、レジスタが自動的に切り替わる。
- 例外発生時に、例外発生要因に対して戻り番地の補正が必要である。
※例外発生要因がパイプラインステージにより異なるので、戻り番地の補正値も異なります。 - リターン命令が存在しない。
- SWI命令(ソフトウェア割り込み)を使用した場合、ソフトウェア割り込み番号が判るレジスタがない。
- プロセッサ制御レジスタが、メモリ空間(4Gbyte)に配置されない。専用命令を使用してアクセスを行うので、全メモリ空間を有効利用することができる。
初期化処理や割り込み処理には、アセンブリ言語が必要でしたが、シンプルで使いやすく、動作の理解を深めるために命令表とサンプルプログラムを見ながらインサーキットエミュレータを使用してデバッグしたことを覚えています。その後、Arm9/Arm11に触れてはみたものの、プロセッサの初期化方法や機能を理解できず、正しく動作させるまで大変苦労しました。今号からスタートするCortex-A入門編によって、多くのエンジニアの皆さんが無駄な苦労なくArmプロセッサを習得する機会になればと願っております。
アーキテクチャの歴史
Armプロセッサが組み込み機器へ利用され始めたv4/v4Tからの歴史について説明します。Armv4Tアーキテクチャで作成された非特権ソフトウェアは、Armv7プロセッサでも使用することが可能です。しかし、Cortex-A8はパイプラインステージが13段で、Cortex-A9は9から12段となり、アーキテクチャがv7-Aでも内部構造が異なりますので、使用するArmプロセッサに合わせてソースコードをビルドすることで最適なコードとパフォーマンスを得ることが可能です。次に、アーキテクチャの歴史について説明します。

アーキテクチャが、v4からv6の世代までは、アプリケーションプロセッサとエンベデッドプロセッサに分けることが可能です。アプリケーションプロセッサは、MMU(メモリマネージメントユニット)を搭載し、仮想メモリを利用することが可能となります。エンベデッドプロセッサは、MPU(メモリ保護ユニット)を搭載し、リアルタイムOSを使用したシステムでも、メモリ保護を行うことができます。例えば、Arm926EJ-Sを使用している場合は、アーキテクチャv5となります。
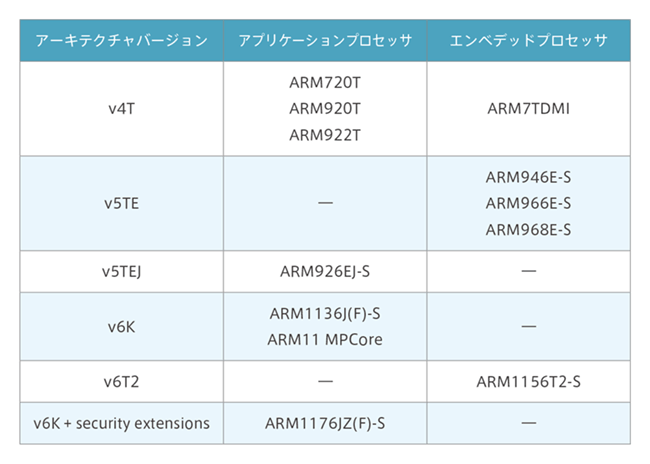
アーキテクチャv7からは、マイクロコントローラプロファイルが増え、3プロファイルとなりました。Cortexシリーズが、全てアーキテクチャv7ではなく、Cortex-M0/M0+/M1はアーキクチャv6になります。
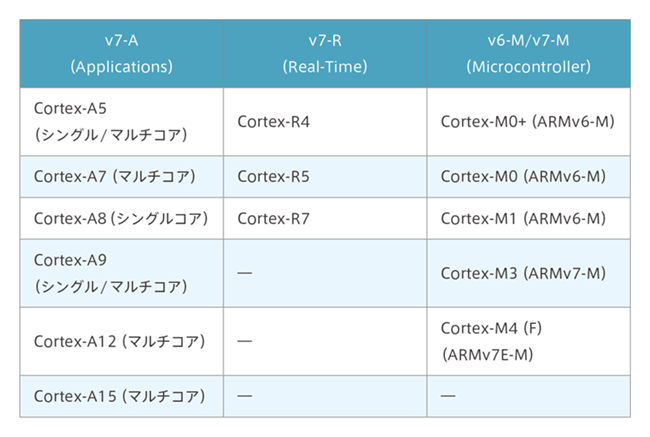
Cortexシリーズについて
Cortexには、Cortex-AとCortex-R、Cortex-Mがあります。AはApplication、RはReal-time、MはMicrocontrollerの各々の頭文字からとりました。もうお気付きだと思いますが、並べるとArmとなります。今回はCortex-Aの解説となりますが3つのシリーズの特長を、簡単に説明します。
Cortex-Aシリーズ
Cortex-AのアーキテクチャはArmv7-Aになります。代表的なシリーズは、Cortex-A9で、性能は2.5DMIPS/MHzを実現することができます。動作周波数は、600MHz~1GHzとなり、シングルコアプロセッサまたは1~4コアのマルチコア論理合成可能プロセッサとして使用可能です。Linux/Androidなどの高機能OS上で、アプリケーションを動作させることができます。特にCortex-A9は、多くの製品が提供されており、リアルタイムOSを搭載した製品にも採用されています。
Cortex-Rシリーズ
Cortex-RのアーキテクチャはArmv7-Rになります。代表的なシリーズは、Cortex-R4で、性能は1.66 DMIPS/MHzを実現することができます。性能的にはCortex-Aシリーズより低いと思われますが、リアルタイム性を確保するために、プロセッサに対してローカル接続された密結合メモリ(TCM)を使用することで、プログラムを迅速に動作させることが可能です。高信頼性システムの構築を行うために、メモリプロテクションユニット(MPU)を搭載し、メモリ保護やデュアルコアロックステップ機能を使うことで、さらなる安全性の向上を実現。デバイスとしての提供は限られていますが、安全性やリアルタイム性への要求が厳しい分野で採用されています。
Cortex-Mシリーズ
Cortex-MのアーキテクチャはArmv7-Mになります。代表的なシリーズは、Cortex-M3で、性能は1.25~1.50 DMIPS/MHzを実現することができます。Cortex-AおよびCortex-Rシリーズと比較した場合、性能は低いとされますが、マイクロコントローラとしては十分に高性能です。リアルタイム制御で重要視される割り込みの応答性に関しても、ネスト型ベクタ割り込みコントローラを搭載することで、使いやすく柔軟な割り込み応答性を実現。高信頼性システムを構築するために、メモリプロテクションユニット(MPU)を搭載することも可能です。
詳細は、Cortex-M編へ。
あわせて読みたい

Cortex-Aファミリについて
Cortex-Aファミリのプロセッサは以下のラインアップで構成されています。
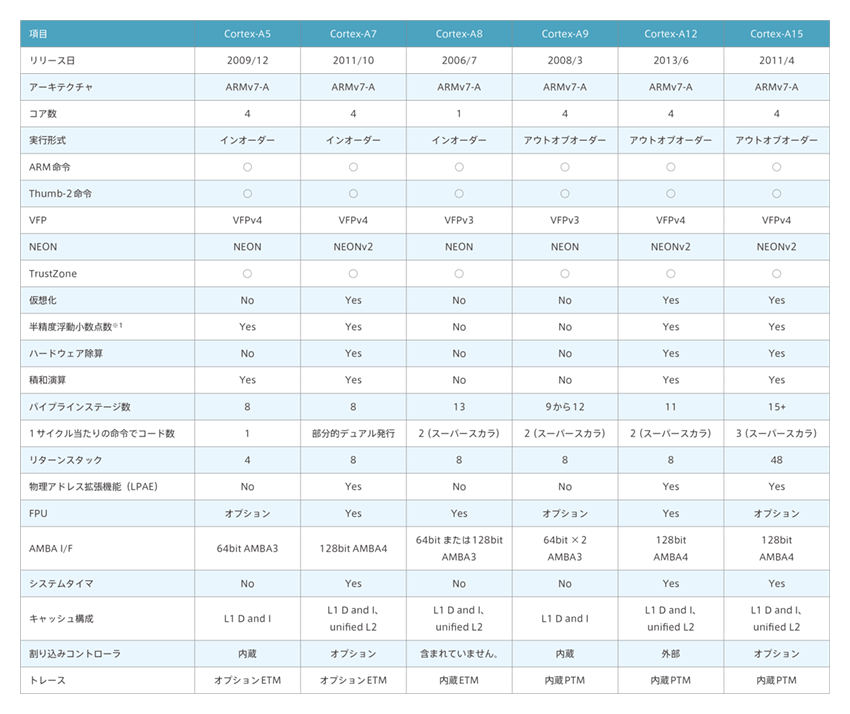
(*1)半精度浮動小数点数とは?:半精度浮動小数点数は浮動小数点方式で表現された浮動小数点数の一種で16ビット形式です。記録や通信などのデータ量の削減が目的で、精度を必要としない用途のためのフォーマットです。IEEE 754-2008で規格化されています。
Cortex-Aシリーズの特徴と機能について
Android/Linuxなどの高機能OS上で、動作するアプリケーションに対応するアプリケーションプロセッサです。その特徴について説明します。
Thumb-2命令セット
Armv6T2で追加された命令セットで、16ビットのThumb命令セットを拡張し、32ビット命令をサポートします。16/32ビットのThumb命令セットの組み合わせにより、Thumb命令セットとほぼ同一のコード密度を達成しながら、32ビットの命令セットのパフォーマンスが実現可能です。従来のArmプロセッサと違い、Cortex-A(*2)シリーズでもハードウェア除算が搭載されています。命令に関しては、「Arm and Thumb-2 Instruction Set Quick Reference Card (Japanese)v4.0」を参照ください。
レジスタセット
32ビット幅のレジスタが16本(r0-r15)あり、プロセッサモードに応じてレジスタの一部が自動的に切り替わります。
アウトオブオーダー実行の対応
プログラム(C/C++等の高級言語でなく、コンパイル結果としての機械語命令レベル)は、順番を守って命令を実行することが一般的です。コンピュータの命令実行効率を上げることを目的としている技術で、「命令の順序を守らない」ことを示しています。プログラムの実行を行う場合、命令の順序で実行しますが、命令によっては順番を変えて実行することで、複数命令の同時実行の可能性を広げる最適化手法の1つです。
ロードストアアーキテクチャ
Armプロセッサは、ロードストアアーキテクチャです。演算(数値演算・論理演算)を実施する場合、レジスタ間で演算を行います。メモリ間で演算を行うことはできません。
非整列メモリアクセスのハードウェア化
RISCプロセッサの場合、構造体メンバーは自然境界(*3)に配置されます。一般的なRISCマイコンの場合、自然境界アクセス機能しかないので、バイト単位でアクセスを行い、論理演算(AND演算、OR演算、シフト演算)を使って該当するデータに変換します。その結果、命令数とデータアクセスバスサイクルが多くなり、実行速度が遅くなります。Armプロセッサの場合は、非整列アクセスをハードウェアで実行するので、命令数の増加を少なくすることが可能です。(バスサイクルは自然境界配置に比較してアクセスサイズが増えますので、パフォーマンスは低下します。)
4GByteのメモリ空間を有効に使用可能
プロセッサの動作設定を行うコプロセッサで各種設定を行います。例えば、MMUの制御およびキャッシュの制御などプロセッサ周辺機能を制御する場合、専用命令を使用してレジスタでリード・ライトを行います。4GByteのメモリ空間を有効に利用することが可能です(*4)。
エンディアンのサポート(*5)
Cortex-Aシリーズの命令は、リトルエンディアンに固定されています。Cortex-Rシリーズの命令は、システムレベルでエンディアンを選択することが可能です。Cortex-Aシリーズのデータアクセスは、ビックエンディアンとリトルエンディアンをサポートします。CPSR(カレントプログラムステータスレジスタ)のビットで制御することが可能です。
CPSR.E:ロードストア命令のエンディアンを制御しますので、プログラム中に動的にエンディアン変換を行うことが可能となります。エンディアン変換を行うことのできる命令(REV命令、REV16命令、REVSH命令)を搭載しています。例外時のエンディアンを選択することが可能で、CP15:SCTLR(システム制御レジスタ、C1)は、EEビットで制御することが可能です。
MMU(メモリ管理ユニット)
MMUはハードウェアページテーブルウォークによる仮想アドレス変換を行います。仮想アドレスを物理アドレスに変換する場合、MMUを使用してアドレス変換を行います。MMUが自動的にTLBを参照し、仮想アドレスから物理アドレスの変換を行います。ページサイズは、4KB/64KB/1MB/16MBで選択することが可能です。ソフトウェアによるTLB管理方式(TLBミス例外による検出)では、ソフトウェアによるエントリテーブルの置き換えが必要ですが、Armプロセッサの場合、ハードウェアによりページテーブルの置き換えを行います。
Cortex MP Coreプロセッサ
マルチコア(最大4コアまで)のシステムを構築することが可能です。SMP(Symmetric Multi-processing:対称型マルチプロセッシング)とAMP(Asymmetric Multiprocessing:非対称型マルチプロセシング)を構成することが可能です。SMP動作時にL1キャッシュのコヒーレンシーと管理するスムープ制御ユニットを搭載しています。
分岐予測機能
Cortex-Aシリーズはパイプライン段数が深く、分岐命令によるペナルティを少なくするために動的分岐予測機能/分岐ターゲットアドレスキャッシュ(BTAC)/リターンスタックを搭載し、分岐命令によるペナルティを少なくする機能を搭載しています。
パフォーマンスモニタユニットとトレース
プログラムパフォーマンスを計測するために、ArmプロセッサはEmbedded Trace Macrocell(ETM)または、Program Trace Macrocell(PTM)を利用していました。しかし、プロセッサの高性能化に伴い、パフォーマンスの変動要因(キャッシュヒット・ミスなど)を正しく把握することが必要になります。プロセッサコアの内部動作状態を把握する機能として、パフォーマンスモニタユニットを搭載しています。
Jazelle
Jazelle-DBX(直接バイトコード実行)により、Javaバイトコードのサブセットをハードウェア内で直接実行できるようになります。
big.LITTLE処理
モバイル機器のバッテリ駆動時間を延ばすための技術です。比較的大型の高パフォーマンスCPUコア(big)と、小型で低消費電力のCPUコア(LITTLE)を組み合わせて省電力化を行います。負荷の高い処理は高パフォーマンスCPUコアで実行を行い、負荷が低い処理は低消費電力のCPUコアに切り替え実行します。Cortex-A15コア(big)とCortex-A7(LITTLE)で構成することで、big.LITTLEの対応を行うことが可能となります。
(*2)Cortex-A7/A12/A15はハードウェア除算命令を実行することが可能です。
(*3)自然境界とは、32ビットデータは32ビット境界に配置し、16ビットデータは16ビット境界に配置します。自然境界に配置することで、データアクセスの効率を上げることが可能です。
(*4)Cortex-Mシリーズは、メモリ空間に配置しています。
(*5)内蔵領域(Cortex-A9 MPCoreの場合は、プライベートメモリ領域)へのアクセスは、リトルエンディアンに固定されます。プライベートメモリ領域では、アクセスサイズの制限がありますので注意が必要です。
Armプロセッサが使うデータサイズ
Armプロセッサが扱うデータは、アーキテクチャに関係なく統一されています。
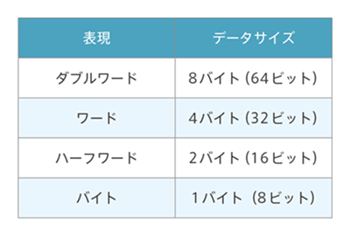
汎用レジスタが扱うデータサイズ
Armプロセッサのレジスタ(r0からr15)が扱えるデータサイズは以下の通りです。レジスタ幅は、32ビットとなるので、ダブルワード(8バイト)を扱う場合は2個のレジスタを使用します。
Cortex-Aシリーズでは、浮動小数点ユニット(以下:FPU)と拡張SIMD(*6)拡張(以下:NOEN)が搭載されています。FPU/NEONはArmv7-Aアーキテクチャでは標準搭載されています。
(*6)SIMD(single instruction multiple data)とは、1命令で複数データの演算を行うコンピュータ並列化の形態を示します。別名、パック演算(パックド演算)やベクトル演算と言います。単一データの演算を行うことを、スカラ演算と呼びます。
Arm浮動小数点アーキテクチャ(VFP)が扱うデータサイズ
Arm浮動小数点アーキテクチャ(以下:VFP)は、半精度/単精度/倍精度の浮動小数点演算をハードウェアによって支援するもので、ソフトウェア ライブラリのサポートによってIEEE 754(*7)に完全準拠します。 VFPv3には32個のダブルワード(64ビット)レジスタが実装されています。Cortex-A9はVFPv3-D16となり、16個のダブルワードレジスタで構成され、VFPv4はCortex-A5/A7/A15に搭載されています。VFP(Vector Floating-point Architecture)はベクトルモードをサポートしていましたが、Armv7-AアーキテクチャではNEONでベクトル演算を行うことが可能となりました。
(*7)IEEE754(IEEE 浮動小数点数演算標準)とは、浮動小数点数の計算で最も広く採用されている標準規格です。IEEE Standard for Floating-Point Arithmetic (ANSI/IEEE Std 754-2008)。
NEONが使うデータサイズ
マルチメディア処理に向いた、8/16/32/64ビットの整数演算と、32ビット (単精度) 浮動小数点演算が1命令で実行可能です。レジスタは、64ビット幅の32個のレジスタ(128ビット幅、16個のレジスタ)として使用可能です。NEONレジスタはVFPレジスタと共用しているため、VFPの32本の64ビットレジスタとNEONと共用でアクセス可能です。
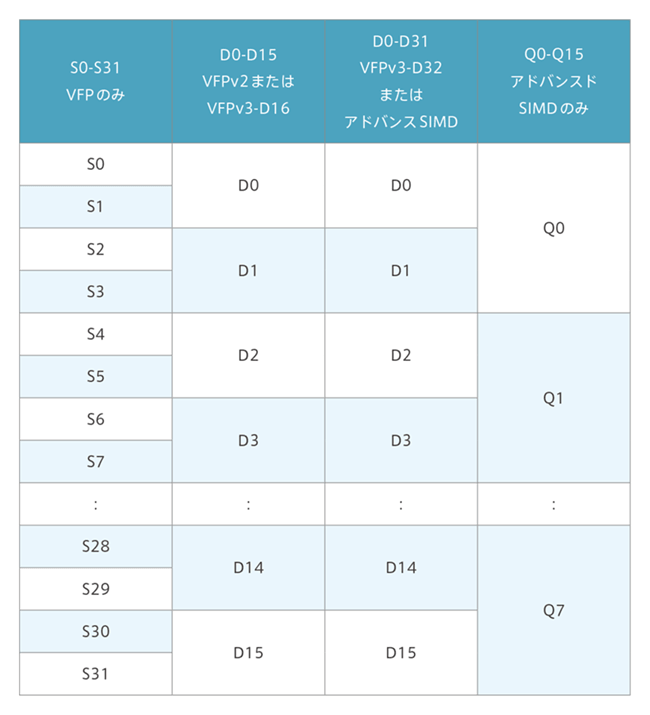
NEONとVFPのレジスタマッピング
Armが定義するエンディアンについて
Armプロセッサは、リトルエンディアンが基本となります。Armプロセッサのエンディアンは、3種類のエンディアンを定義しています。一般的なリトルエンディアンはLE、ビックエンディアンはBE-8となり、アーキテクチャv7では、BE-32はサポートしていません。
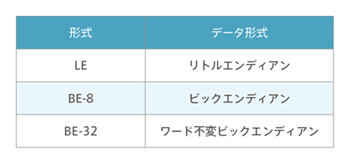
エンディアンの形式 / データ形式

LE(リトルエンディアン)形式

BE-8(ビックエンディアン)形式
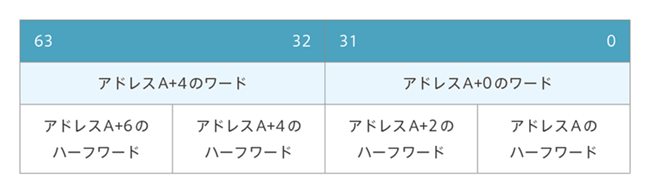
BE-32(ワード不変ビックエンディアン)形式
プロセッサマニュアルの見方
Armプロセッサを使用する際、マニュアルの見方にコツがあります。
①アーキテクチャ:Armv7-A/RがArmプロセッサの基本
- Armアーキテクチャリファレンスマニュアル「Armv7-A及びArmv7-Rエディション」
②ご利用のArmプロセッサのテクニカルリファレンスマニュアル
Cortex-A9を使用する場合は、次の4種類のマニュアルを読んでいただくくことが必要になります。
- Cortex-A9 テクニカルリファレンスマニュアル
- Cortex-A9 MP Coreテクニカルリファレンスマニュアル
- Cortex-A9 NEONメディア処理エンジンテクニカルリファレンスマニュアル
- Cortex-A9 浮動小数点ユニットテクニカルリファレンスマニュアル
③使用するデバイスベンダーの提供マニュアル
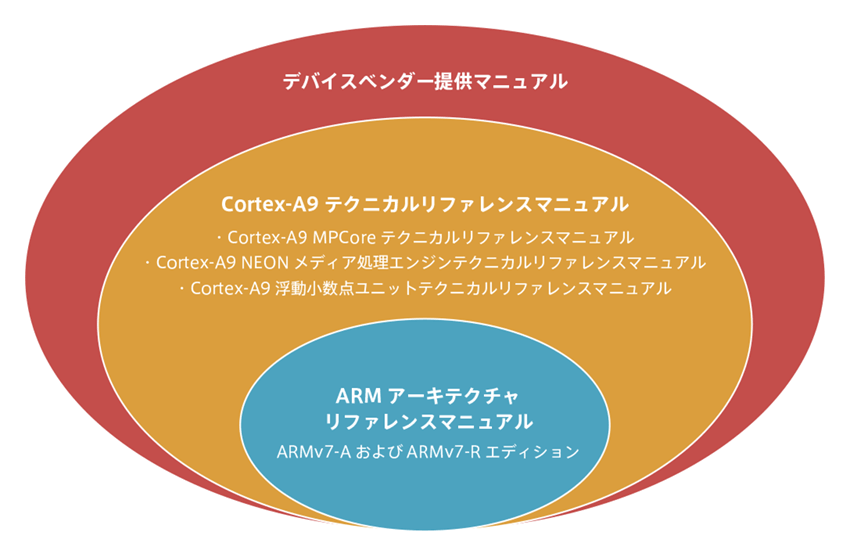
上記の順番に学んでいただくことで、ご利用されるCortex-Aプロセッサの理解が深まります。しかし、これだけ大量のマニュアルを読むのも大変です。
Cortex-Aシリーズのプログラミングを効率良く学ぶには、「Cortex-Aシリーズ プログラマガイド(バージョン1.0日本語版)」がお勧めです。
【日本語版】「Cortex-A シリーズ プログラマガイド」
【英語版】「Cortex-A Series Programmer’s Guide Version: 4.0」

こちらも是非



“もっと見る” Cortex-A編

初期化処理
リセット例外からmain()関数を呼び出すまでの初期化は、ユーザが作成する部分とArmコンパイラが実行する部分に分けることができます。コードのコピーや初期化変数/未初期化変数の初期化は、リンカのメモリ配置設定を処理系ライブラリが実行します。
PMU(パフォーマンス監視ユニット)
PMUに関連するレジスタは、ユーザモードでのアクセスは禁止されていますので、PMUSERENR(ユーザイネーブルレジスタ)を特権モードでユーザモードアクセス許可を設定します。PMUSERENRについては、 後述の該当項目を参照ください。
TrustZone(セキュリティ拡張機能)
TrustZoneはCortex-Aシリーズの拡張機能で、大規模OSやアプリケーションが動作するノーマルワールドとセキュリティ関連が動作するセキュアワールドを導入しています。TrustZoneでは、ノーマルワールドメモリ空間とセキュアワールドメモリ空間の分離が可能です。