





Pipeline processing (temporal parallel processing)
Pipeline processing is parallel processing that decomposes one operation into multiple partial operations, prepares units that can process each independently and simultaneously, and operates in parallel.
For example, a series of operations from reading instructions from memory, performing an operation, and storing the result of the operation in a storage device (memory or register) are divided into the following units.
- A unit that reads instructions (fetch)
- Unit for decoding and translating instruction codes (decoding)
- The unit that performs the operation (operation)
- Unit for storing calculation results in a storage device (storage)
Each unit does its own work completely independent of the others.It usually takes one clock to finish the job and send the results of the process to the next unit.I don’t care what the other units are doing, I just do my job in one cycle.
In the above case, the processing of a single instruction is completed in four steps from “1” to “4”, so it is called a four stage pipeline.In reality, 4 cycles are required for each instruction, but since each unit processes in parallel and the “4” processes produce the result every cycle, it appears that one instruction can be processed in one cycle.
The advantages and disadvantages, to name a few, are as follows
- advantage
- Suitable when the same kind of operation is performed continuously (for RISC)
- The hardware gets smaller.
- disadvantage
- It’s counterproductive to simple operations.
- You can’t make the parallelism extremely high(A pipeline failure would reduce efficiency)
Cortex-M3 pipeline processing
Cortex-M3 is a three-stage pipeline, which means “fetch”, “decode” and “operation (including storage)”.The figure below shows a diagram of the Cortex-M3 pipeline sequence.
- Step 1: Fetch an instruction from Flash (F)
- Step 2: Decode (decode – translate) the instruction (D)
- Step 3: Operate and write the result (E)
From the AND instruction of 0x8FEC to the EOR instruction of 0x8FF0, pipeline processing is performed without any obstacles, and the result of the operation is output every cycle, so it is one cycle of one instruction.
However, if there is a conditional branch instruction such as the BX r5 instruction in 0x8000, we have to wait for the result of the BX r5 instruction because the result of the operation will determine whether the operation will continue with the SUB instruction in 0x8002 or branch into the AND instruction in 0x8FEC.This interrupts the pipeline processing.This kind of interruption in pipeline processing is called a pipeline failure.In addition to branching instructions, a pipeline failure occurs even when the result of one instruction is used as an operand for the next instruction, called Read After Write.
Cortex-M3 has a function to calculate the branch destination in advance in order to minimize the damage in case of such a pipeline failure.We call that function branching speculation. The example below is a loss of two cycles.
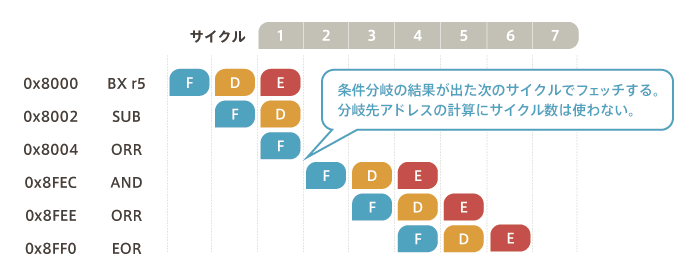
Cortex-M3 pipeline sequence

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …