





Timing of exception handling
If you read the Cortex-M3 manual, you’ll see the words tail-chain, sidestep, and rear-end.This word indicates the timing of exception handling that occurs according to the exception handling priority.A brief explanation of the meaning of each is as follows.
tail chain
Refers to the state of moving from a running interrupt to another interrupt.It is continuous interrupt processing with no overhead in storing and restoring state between interrupts.
usurpation
A new exception raised during interrupt processing is an interruption to the flow being processed.
Late arrival
If an interrupt with a higher priority occurs during state saving due to interception, the This means switching to processing for the interrupt with the highest priority, and starting vector fetching of the interrupt. Basically, it’s a mechanism that aims to speed up the set-aside.
tail chain
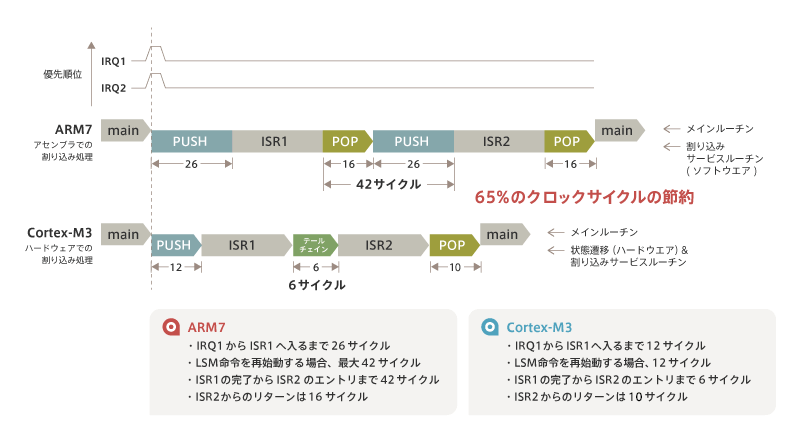
Let’s consider the case where two interrupts with different priorities come in at the same time.The one with the higher priority is called interrupt 1 (the service routine for this interrupt is called ISR1).The lower one is interrupt 2 (the service routine for this interrupt is called ISR2).The processor will (of course) run ISR1 first, then ISR2.
For example, in Arm7, it pushes the context of the processor before entering ISR1.Then, when ISR1 is finished, it POPs.Next, we do a push for ISR2. However, if you POP and then immediately push, the stack value will not change because you are pushing and POPing the same context.In other words, it is a completely useless operation.So, in Cortex-M3, this PUSH and POP will not be done.However, since the service routine for interrupts is changed, some internal logic needs to be handled. This period of internal processing is called the tail-chain.
Only six clock cycles are required for the tailchain.In the case of Arm7, it takes 42 clock cycles to move from ISR1 to ISR2 after push and POP.In addition, the Arm7 took 26 clock cycles for PUSH, while the Cortex-M3 only has 12 clock cycles.POP also takes 16 clock cycles on Arm7, but has been reduced to 12 clock cycles on Cortex-M3.Overall, comparing Arm7 to Cortex-M3 shows a clock cycle savings of 65%.
usurpation (POP usurpation of ISR)
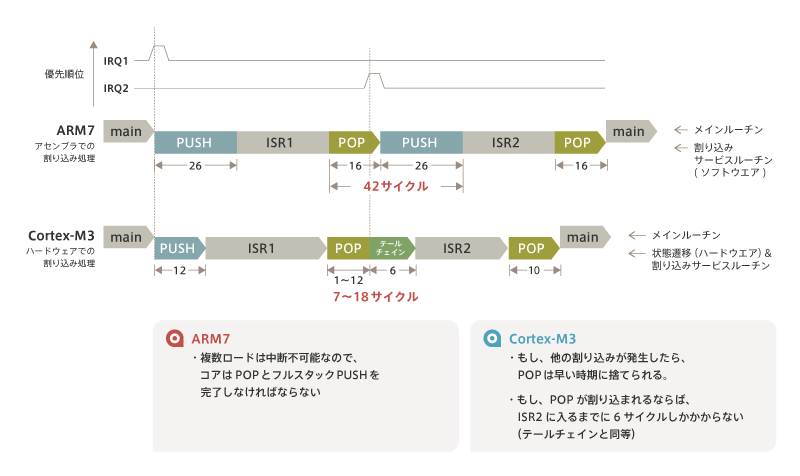
Consider the case of two interrupts with different priorities (IRQ1 and IRQ2, with IRQ1 having the higher priority).In this case, it’s not at the same time, but the one with lower interrupt priority enters later.This would be the case if it occurred during the return from ISR1 to the main routine (POP), rather than after the first ISR1 has been fully processed.
In Arm 7, IRQ2 is accepted during the processing of ISR1 POP and ISR2 is pushed as soon as ISR1 POP ends.As I mentioned in the tailchain, POP and PUSH are the same context-introducing and context-introducing actions, so they’re useless.So, in Cortex-M3, we’re going to do something that omits this behavior.
The Cortex-M3 interrupts the POP of ISR1 as soon as IRQ2 enters and immediately goes into the tail-chain process.However, with the Cortex-M3, POP takes 16 cycles, but cannot be interrupted when IRQ2 enters after the 12th cycle.In that case, POP will be completed and push for ISR2 will start.If the POP of ISR1 is from 1 to 12 cycles, then it will move to the tail chain, so the loss time will be up to 12 cycles.After moving to the tail chain, ISR2 is executed and finally POP of ISR2 is executed to return to the main program.
usurpation (POP usurpation of ISR)
usurpation (in the middle of ISR)
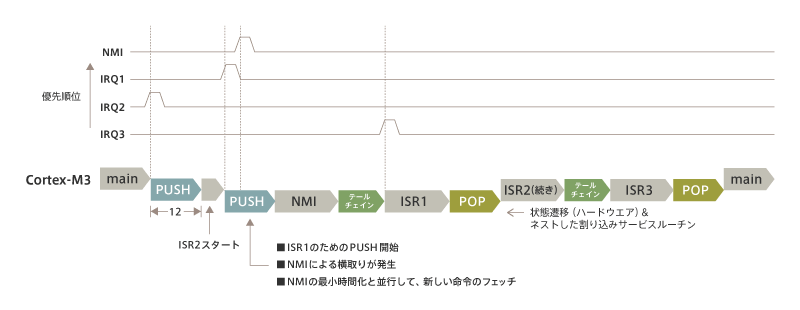
When explaining interruptions to customers, the one thing they always ask is nesting.If another high priority interrupt is received during the ISR, it will be nested.This is also a type of usurpation, so I’ll explain the nesting example next.In this case, there are a total of four types of interrupts, including the NMI, at complex times.In order of priority, NMI, IRQ1, IRQ2, and IRQ3 are ranked in descending order.
First, IRQ2 enters, followed by a push and then ISR2. After that, IRQ1 enters.ISR2 has started, so the context has changed. Therefore, it is necessary to push and save the context.So, ISR2 is interrupted and a PUSH for ISR1 begins. This is the start of the so-called nesting.
However, in the middle of this PUSH, an even higher priority NMI comes in.So a PUSH that starts with ISR1 is usurpated to the NMI, and after the PUSH, the NMI service routine is executed.
IRQ1 has been accepted, but the NMI has been processed first, so it is awaiting processing.When the NMI service routine is over, ISR1 starts after the tailchain because the conditions are the same as in the case of the tailchain described at the beginning.The context has not changed, so there is no PUSH here.
During the tailchain from the NMI service routine to ISR1, IRQ3 is entered.IRQ3 has the lowest priority, so it is not executed here and is put into a wait state.
When ISR1 is over, we go back to ISR2, but Now, before entering the NMI service routine, we need to POP the context that we pushed.After the POP is complete, ISR2 resumes from the next interrupted program counter (PC).
When ISR2 is over, we move on to ISR3. As you’ve probably guessed by now, we’re moving to the ISR3 here too with only 6 cycles of tailchain.At the end of ISR3, it POPs the context that was pushed before entering ISR2, terminates all interrupt processing, and returns to the main program.
Thus, even when four interrupts occur at complex times, the Cortex-M3’s NVIC automatically selects the most efficient steps to handle with the least overhead.
usurpation (in the middle of ISR)
Late arrival
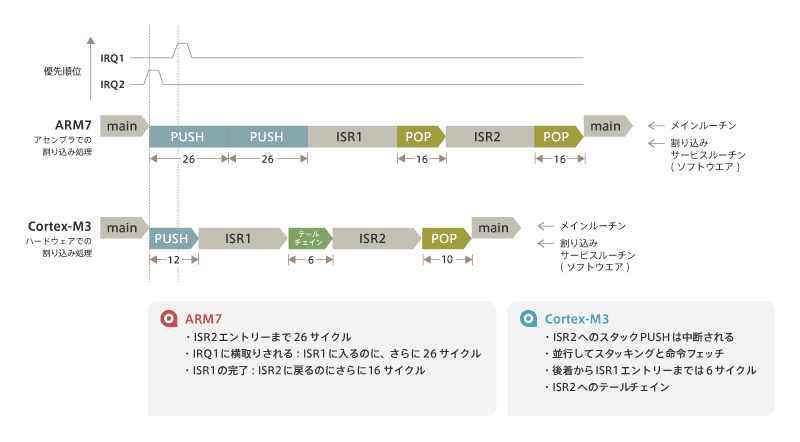
Next, I’m going to start executing low priority interrupts once.In this example, during PUSH, a higher priority interrupt comes later and the PUSH is usurped.We call it a late arrival because the higher priority interrupts come later.This time, it is the relationship between IRQ1 and IRQ2, where IRQ1 has a higher priority.
IRQ2 will be accepted first and then push will start. However, during this PUSH, IRQ1 occurs.Therefore, IRQ2 is put on hold and the running PUSH is switched to ISR1.
In Arm7, I do a PUSH for ISR2 and a subsequent PUSH for ISR1 and move to ISR1, but I think you can quickly see that it’s a wasteful process because even if you do two consecutive PUSHs, you’re just stuck in the same context.
In the Cortex-M3, ISR1 is executed after one PUSH and ISR2 starts after the tailchain when ISR1 ends.As you can see by now, POP on ISR1 will not be executed.When ISR2 finishes, it will POP one last time to end the interrupt process.
Summary of Exception Priorities
We’ve looked at tail chaining, usurpation (two types), and late arrival, but in all of these cases, the most important thing in interrupts – how to efficiently handle multiple interrupts according to the priority of the interrupts – is achieved in Cortex-M3 using NVIC hardware.
A long time ago, when I was designing a 16-bit microcomputer, I felt that designing an interrupt controller was the hardest part.The number of events that have to be assumed is tremendous.Of course, CPU design is also very difficult to think about what kind of processing needs to be done in many cases, but in the case of CPU, the number of events can be limited to a certain extent in each pipeline processing.If it’s a three stage pipeline, it’s the number of events to the third power, and if it’s five stages, it’s the fifth power, resulting in a tremendous case division.However, by delimiting it with a pipeline, it is easier to design and less buggy.
However, since interrupt controllers at that time consisted of random logic, it was very difficult to first assume events and then to combine the logic for each of those cases.Even after it was completed, when we ran the logical simulation, many unexpected bugs appeared, and we proceeded with the design while worrying that the bugs would not be resolved.Now, we do the logical design with functional descriptions, but the number of events that we have to assume does not change. Rather, since the performance of the CPU has improved, it may be more difficult than in the past.
From someone who has designed an interrupt controller, the Cortex-M3’s NVIC is a pretty good interrupt controller.

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …