





Changes from Cortex-M4
In September 2014, the Cortex-M7 was announced as the top successor to the Cortex-M4.More than a year before that, rumors circulated that a new Cortex-M was being fleshed out, and some Arm users were calling it by its temporary name, Cortex-M5.However, since no information came in and the actual situation was unknown, I was looking forward to seeing what kind of core would emerge.When the new Cortex came out, it was an M7 instead of an M5, which took everyone by surprise, but what was even more surprising was the extreme improvement in performance.It has a six-stage pipeline and even more dual superscalar construction.CoreMark/MHz has improved from 3.4 on the M4 to 5.04 on the M7. The DMIPS/MHz has also been improved from 1.25 to 2.14.
A part of the bus interface is Cortex-A, so it looks like a processor even though it’s a microcontroller.Here are some of the major changes from the Coretx-M4.
- Six-stage pipeline super scalar
- Memory interface improvements and additions
- on-board cache
- double precision floating point arithmetic
On the other hand, the Cortex-M7 no longer supports the “bit-band feature”.
Cortex-M series performance comparison
| benchmark | Performance | ||||
|---|---|---|---|---|---|
| M0 | M0+ | M3 | M4 | M7 | |
| CoreMark/MHz | 1.99 (*7) | 2.15 (*6) | 3.32 (*5) | 3.4 (*3) | 5.04 (*1) |
| DMIPS/MHz | 0.90~0.99 (*4) | 0.93~1.08 (*4) | 1.25~1.50 (*4) | 1.25~1.52 (*4) | 2.14 / 2.55 / 3.23 (*2) |
(*1)CoreMark 1.0 : IAR Embedded Workbench v7.30.1 –endian=little –cpu=Cortex-M7 -e -Ohs –use_c++_inline –no_size_constraints / Code in TCM – Data in TCM。
(*2) The first result complies with all the “basic principles” set forth in Dhrystone’s documentation.The second allows inlining of functions, not limited to the allowed C-string libraries.The third allows further simultaneous (“multi-file”) compilation.All using the original (K&R style) Dhrystone v2.1.
(*3)CoreMark 1.0 : IAR Embedded Workbench v6.50 –endian=little –cpu=Cortex-M4 -e –fpu=None -Ohs –use_c++_inline –no_size_constraints
(*4) Minimum value with inlining off (per Dhrystone’s recommendation) and maximum value with inlining on (reported for other processor architectures).Dhrystone v2.1。
(*5)IAR ANSI C/C++ Compiler V6.60.1.5097 for Arm -Ohs –no_size_constraints。
(*6)CoreMark:1.0:21.46 /Arm C compiler 5.03 [build 24] -O3 –loop_optimization_level=2 -Otime -DMICROLIB –library_type=microlib –cpu=cortex-m0 / FPGA Platform, SRAM Code – SRAM Data, Memory and CPU Clock: 10MHz.
(*7)CoreMark:1.0:19.92 /Arm C compiler 5.03 [build 24] -O3 –loop_optimization_level=2 -Otime -DMICROLIB –library_type=microlib –cpu=cortex-m0 / FPGA Platform, SRAM Code – SRAM Data, Memory and CPU Clock: 10MHz.
Superscalar (spatial parallel processing)
A superscalar is an architecture that performs fully parallel processing.For example, multiple instructions are fetched and decoded at the same time, and multiple ALUs can perform simultaneous operations.It is obvious that the performance is better with two processing units than with one, but Since the hardware is doubled, it is only used in microcomputers that require more processing power.Incidentally, an old technical book, together with a pipeline, summarized the following.
- The most direct parallel processing, in which several hardware (units) that can perform a certain operation simultaneously are arranged in a row and operated simultaneously.
- Very effective.
- The hardware gets bigger.
- If the hardware and processing timing do not match, the hardware utilization rate will be poor.
Pipeline processing (temporal parallel processing)
- Parallel processing that decomposes a single operation into multiple partial operations, prepares units that can independently process each of them simultaneously, and runs them.
- Suitable for continuous operation of the same kind (for RISC).
- It is counterproductive to simple operations.
- It is not possible to increase the parallelism to an extreme.
The Cortex-M7 can be summarized in terms of performance, energy efficiency, and safety as follows.
Performance and Configurability
- Dual six-stage pipeline
- Powerful integer, floating-point and DSP arithmetic performance
- Flexible system/memory interface : TCM, AXI, AHB
- Harvard cache (instruction cache 0 to 64 KB, data cache 0 to 64 KB)
energy efficiency
- Clock gating, WIC (Wake-up Interrupt Controller)
- Same sleep mode as Cortex-M3/M4
- Supports multiple power domains and state retention
safety
- Memory ECC (SEC-DED), MPU, MBIST, Lockstep Operation, Full Data Trace, Safety Manual
- Debugging and tracing
- ETMv4 Instruction and Optional Data Trace
- Serial Wire SW and JTAG
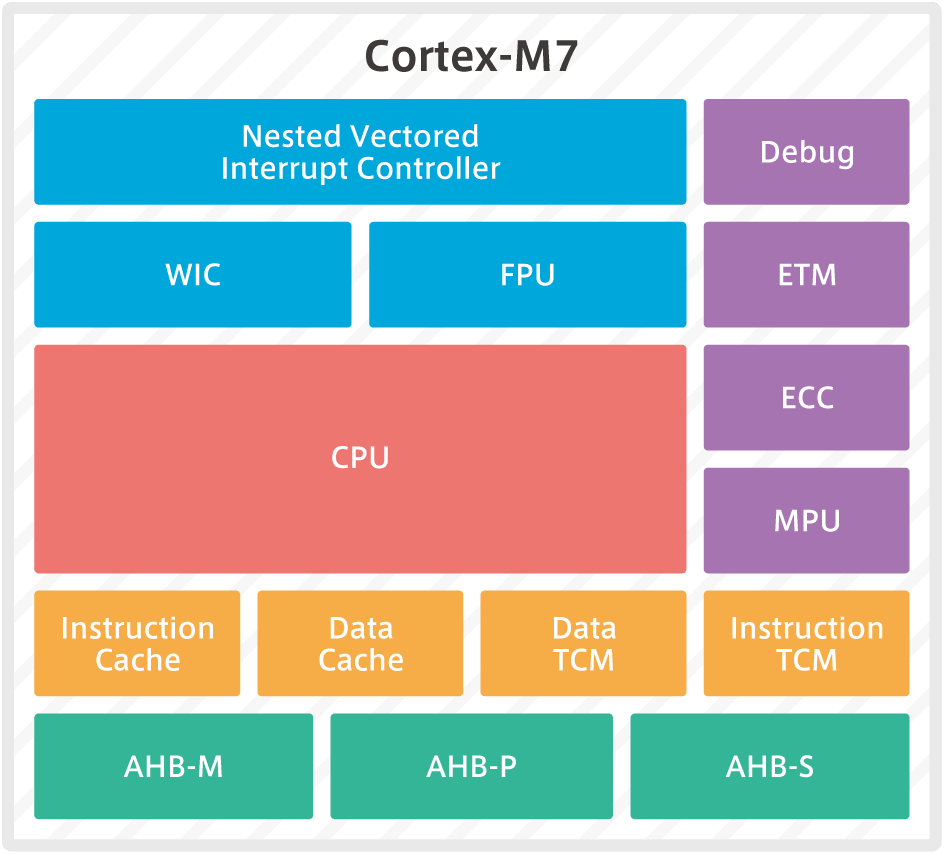
In terms of architecture, it can be summarized as follows.
Arm v7E-M architecture
- v7E-M : Cortex-M4 superset
- Thumb2 (16-bit + 32-bit instructions) only (no Arm instructions supported), double precision floating minority instruction added to Cortex-M4
- memory-mapped architecture
- Single or double precision floating point unit (optional)
- Hardware for interrupt handling with low overhead (NVIC)
- Built-in system timer (SYSTICK)
The main new features that have been added and those that have been removed are as follows.
new feature
- Improved floating point instruction – double precision (new instruction)
- cash maintenance
- Improving breakpoints
Cortex-M4 to Cortex-M7 compatibility issues
No bit-banding (no code compatibility with Cortex-M3 or M4)
memory map
It is a memory-mapped architecture.The periphery of the core (NVIC, system control, debug…) is allocated to the private peripheral bus (PPB) area.It has two different interfaces, instruction fetching and data access, and is modified to be more versatile than the I-bus, D-bus, and S-bus from Cortex-M3/4.
interface
- AXI Master (AXIM): includes instruction and data caches (optional)
- ITCM(Instruction Tightly Coupled Memory)
- DTCM(Data Tightly Coupled Memory)
- AHB Peripheral port(AHBP)
- AHB External Peripheral Port(EPPB)
interface access
- Type of access – instruction fetch or data access
- address access
- Control settings (TCM and AHBP)
- The fixed map determines which interfaces are accessed.
Cortex-M7 comparison summary
| item | Content |
|---|---|
| architecture | Arm v7E-M |
| DSP Extensions | Single-cycle 16/32-bit MAC |
| Single-cycle dual 16-bit MAC | |
| 8/16-bit SIMD (Single Instruction Multiple data) calculation | |
| Hardware division (2 to 12 cycles) | |
| floating-point unit | Single or double precision floating point unit (optional) |
| IEEE 754 compliant | |
| pipeline | Dual 6-stage super scalar pipeline (with branching prediction) |
| performance efficiency | 5.04 CoreMark/MHz (see preamble) |
| 2.14 / 2.55 / 3.23 DMIPS/MHz (see foreword) | |
| interconnect | 64-bit AMBA4 AXI, AHB peripheral ports (64MB to 512MB) |
| instruction cache | 0 to 64 KB 2-way assocative type with optional ECC |
| data cache | 0 to 64 KB 4-way assocative type with optional ECC |
| Instruction TCM | 0 to 16 MB (ECC is optional) |
| data TC | 0 to 16 MB (ECC is optional) |
| memory protection | Optional 8- or 16-region MPU with sub-regions and background areas |
| interruption | Non-maskable interrupts (NMI) + 1 to 240 physical interrupts |
| interrupt priority level | Priority levels from 8 to 256 |
| wake-up interrupt controller | Up to 240 wake-up interrupts |
| sleep mode | sleep mode |
| Sleep signal and deep sleep signal | |
| Optional Retention Mode when using Arm Power Management Kit | |
| bit manipulation | bit manipulation |
| debug | Optional JTAG port and SW (Serial Wire Debug Port).There are up to eight breakpoints and four watchpoints. |
| trace | Optional instruction/data trace (ETM), data trace (DWT), and instrumentation trace (ITM) |
block diagram
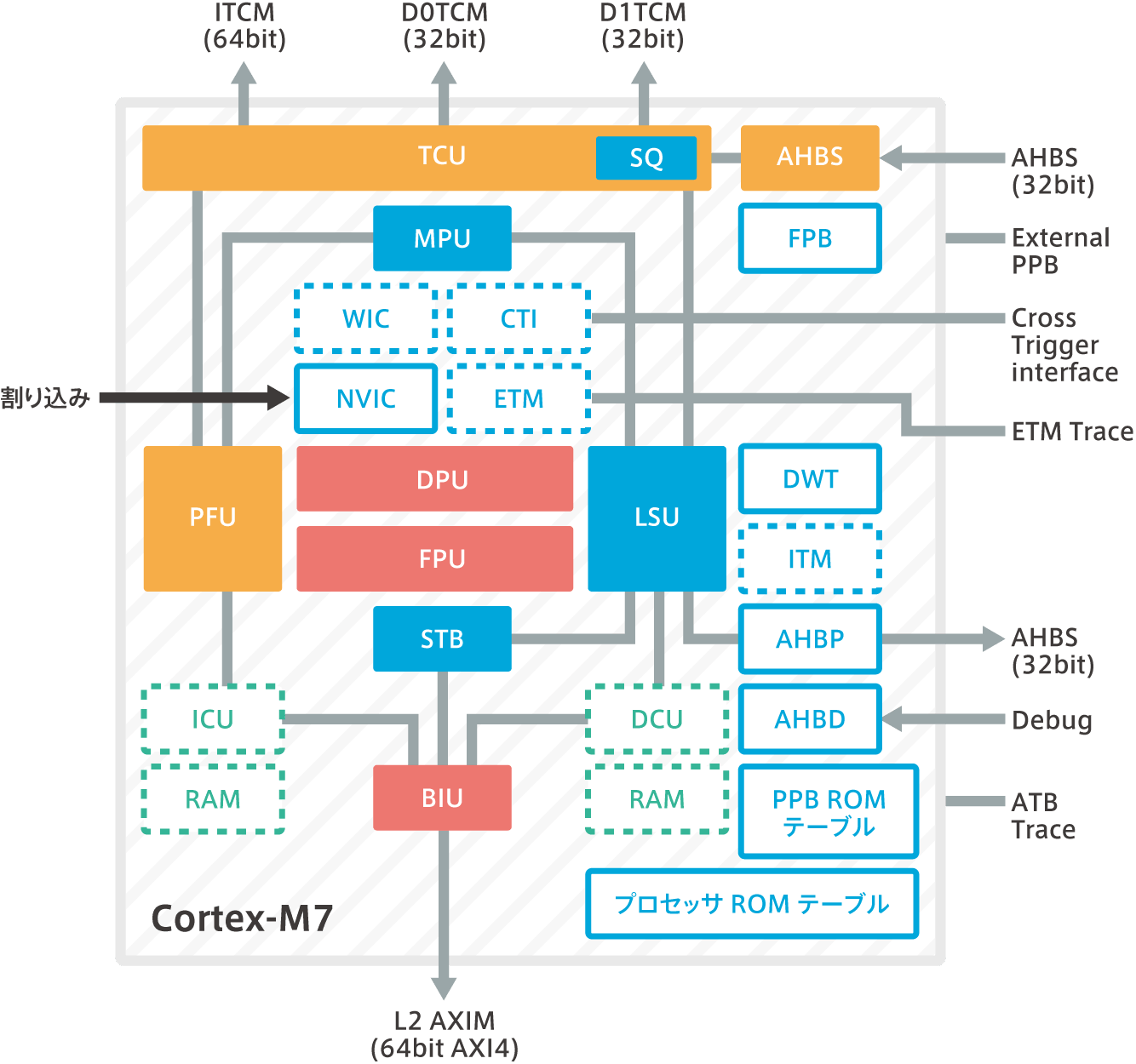
Prefetch Unit (PFU)
- 64bit instruction fetch
- 4x64bit prefetch queue: Separates instruction prefetching from the DPU pipeline.
- Branch Target Address Cache (BTAC): 64 entries to perform branch predictive state and target address inversion in a single cycle.
- Static branch prediction when BTAC is not specified.
- Transfer of flags for early determination of direct branching of the decoder, also the first execution step of the processor pipeline.
DPU:Data Process Unit
- A parallel integer register file for large scale dual issue (Issue: 2nd decode).6 read ports and 4 write ports.
- Dual shifter.
- Transfer logic that minimizes interlocking.
- Dual ALUs, plus a built-in ALU for SIMD instruction execution.
- A single-MAC pipeline performs 32x32bit + 64bit → 64bit operations in two cycles, and achieves a throughput of one MAC per cycle.
- Built-in division unit: With a function that judges the content of the operand and terminates early.
LSU:Load Store Unit
- 64bit load channel (dual 32bit load channels)
- The 32bit dual issue (Issue) is Load to TCM and AXIM (64bit load width and dual 32bit load capabilities) and D-cache.
- Single 32-bit load channel for the AHB interface.
- 64bit store channel 1ch
- Isolated STB (Store-Buffering) for TCM and Quality of Service (QoS) for AHBP and AXIM.
AHBD interface
- The AHB-Lite Debug (AHBD) interface provides debug access to the Cortex-M7 processor and a complete memory map.
AHBP Interface
- The AHB-Lite peripheral device (AHBP) interface provides suitable access to system peripherals with short overhead times.
- Provide support for unaligned memory access.
- It provides buffers for write data and exclusive access for multiprocessor systems.
FPU
- A single pipeline optimized for single precision (SP).
- 1SP MAC/cycle throughput.
- Integer pipelines support parallel execution.
- Automatic stacking of floating point contexts.
- Deferred until the start of an interrupt service routine (ISR) that executes a floating-point instruction.This reduces the wait time to enter an ISR and removes the stacking of floating-point contexts for unused ISR.
- Single precision instruction (C language Float type) data processing operations.
- Double precision instruction data processing operations are optional.
- An instruction that combines multiplication and accumulation to increase accuracy (Fuse MAC).
- Hardware supports conversion, addition, subtraction, multiplication and optional accumulation, division and square root.
- Hardware supports denormalization numbers and rounding to all IEEE standards 754-2008.
- 32 32-bit single-precision registers or 16 64-bit double-precision registers.
TCU:Tightly-Coupled interface Unit
- Supports external ECC logic and AHB Slave (AHBS) interfaces for system access to the TCM.
BIU:Bus Interface Unit
- Configurable AMBA 4 AXI interface to support high performance L2 systems.
- Enhanced AHB-Lite interface: low overhead interface to system peripheral functions.
- Instruction and data cache and controller with optional error correction function (ECC).
Nested Vectored Interrupt Controller (NVIC)
- NVIC are placed close to the core to handle interrupts with low overhead.
- 1 to 240 external interrupts.
- You can set the priority order from 8 to 256.
- The interrupt priority can be dynamically changed.
- Grouping of priorities. This allows the user to select whether the interrupt level is preempted or not preempted.
- As with the Cortex-M3/M4, it supports tail-chaining.This eliminates wasted pushes and POPs between ISRs and minimizes overhead.
Wake-up Interrupt Controller:WIC
- Control the return from Ultra Low Power Sleep Mode.
Memory Protection Unit:MPU
- Protect the memory.
- Enables efficient use of up to 16 memory areas and Sub Region Disable (SRD).
- Enables a background area to enforce the default memory map attribute.
PPB ROM table
- The two ROM tables enable debugger identification and allow connection to the “CoreSight” debug.
Cross Trigger Interface Unit(CTI)
- CTI allows debug logic and ETM to communicate information to each other and to other “CoreSight” components.
Embedded Trace Macro(ETM)
- The ETM provides the ability to trace data with instructions only, or instructions when set.
AHBS Interface
- Enhanced AHB-Lite interface to support system peripherals with short weight cycles.
ICU
- Instruction cache unit and RAM
DCU
- Data cache unit and RAM
Other memory systems
- Instruction and data caches and error correction code (ECC) control.
- Memory Build-in-Self-Test Interface (MBIST). Supports MBIST while the processor is running.
Debug and trace components
- The FPB (configurable breakpoint unit) sets the breakpoints.
- DWT (Configurable Data Watchpoint and Trace) configures watchpoints, data traces, and system profiling.
- The ITM supports printf () debugging.
- The interface is optimized for
- On-chip data is sent to TPA (Trace Port Analyzer), including SWO (Single Wire Output) mode.
- The debugger accesses all the memory and registers in the system.This includes the memory-mapped device and the internal core registers when the core is halt.Then, even when the reset is asserted, the debug control register is accessed.

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …