





目次
- Execution Pipeline (ALU)
- Execution Pipeline (MAC)
- Execution pipeline (divider)
- Execution pipeline (load/store)
- Execution pipeline (branches)
- Execution Pipeline (FPU)
- Execution pipeline (instruction end)
- Execution pipeline (prefetch unit)
- Execution Pipeline (Branch Target Address Cache)
- Execution pipeline (number of branch divisions)
Execution Pipeline (ALU)
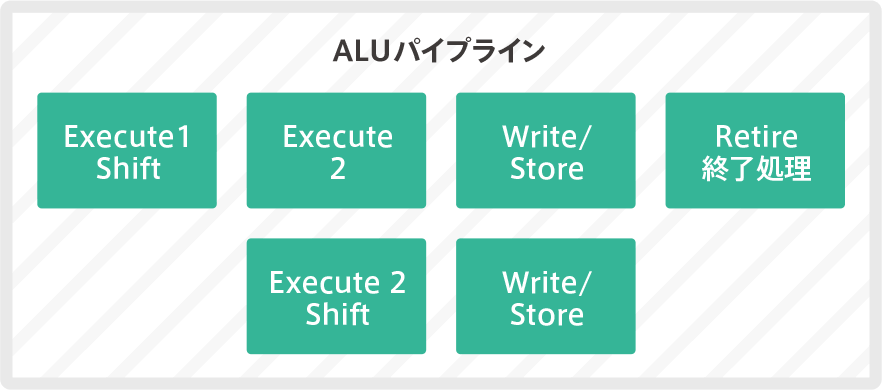
ALU
This execution pipeline executes the data processing instructions.Specifically, arithmetic operations, logic operations, saturation operations, bit manipulation instructions, and packing.
It has two 32-bit ALUs.Rather than having two exactly the same ALUs, it’s a main and sub relationship.SIMD instructions are computed by the main ALU and not by the sub, which is why dual issuance as mentioned above is not possible.
Each ALU has two shifters, one for each ALU, but the usage is slightly different.The main ALU performs shift and simple operations in two consecutive stages, while the sub-ALU performs either shift or simple operations in a single stage.
Some Thumb2 instructions combine shifting with other operations, such as shifting, and in such cases, it is necessary to perform the shifting operation and then perform the simple operation.For this reason, the execution timing of the two shifters is delayed. On the other hand, Simple Shift allows for simultaneous issuance and execution.
Execution Pipeline (MAC)

MAC
It is a single MAC pipeline. This execution pipeline mainly performs multiplication, accumulation, and sum-of-product operations.
A single MAC pipeline performs 32bit x 32bit + 64bit → 64bit operations in two cycles, resulting in a throughput of one MAC per cycle.Since it has a two-stage structure, multiplication is calculated in the first cycle, and addition (accumulation) is performed in the second cycle.
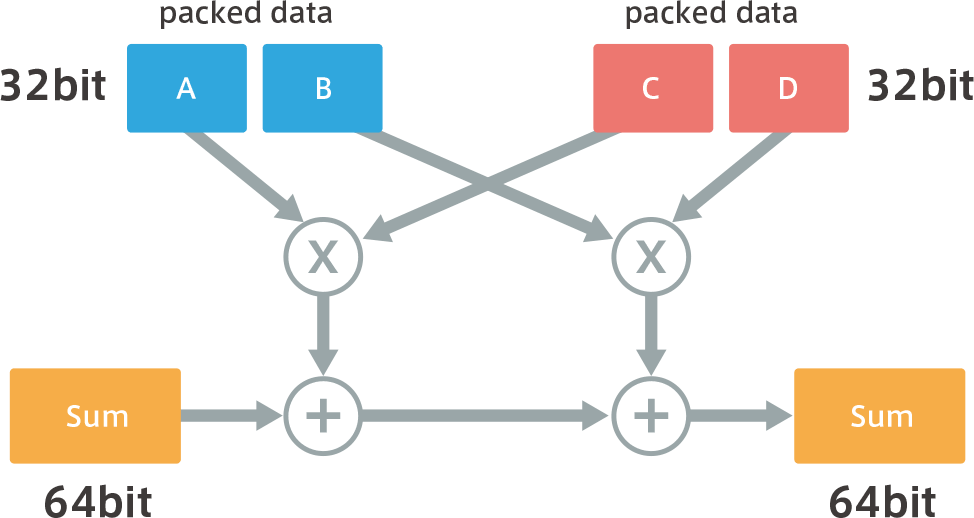
The ISA (Instruction Set Architecture) for Cortex-M7 and Cortex-M4 is the same Armv7-M. Therefore, the pack data method is used for the sum-of-product operation.Packed data means that 32 bits of data are divided into 16 bits and then arithmetic operations are performed and the results are packed back into 32 bits of data. (See above). To achieve this, the interior of the Mac must consist of an array of four 16×16 signed multipliers.
Execution pipeline (divider)
divider
As described in the chapter “Block Diagram (see Part 1)”, the DPU (Data Processing Unit) has a division unit. This unit supports SDIV (signed division) and UDIV (unsigned division).
It is equipped with the ability to determine the content of the operand and terminate it early. If the size of the number to be divided and the number to be divided are close, the execution cycle will be shorter. It takes a minimum of 2 cycles and a maximum of 12 cycles.
The division is performed in the cycle of the ALU pipeline. And since there is only one divider on board, the next division instruction will not be issued until the divider has been calculated (i.e., until the divider is in an unused state) and will stall.The division is performed between general-purpose registers. If the value of Rn is not divisible by the value of Rm, then the result is rounded to zero.
Also, if CCR.DIV_0_TRP is set to 1, if it is divided by 0, an exception will be executed.
Execution pipeline (load/store)
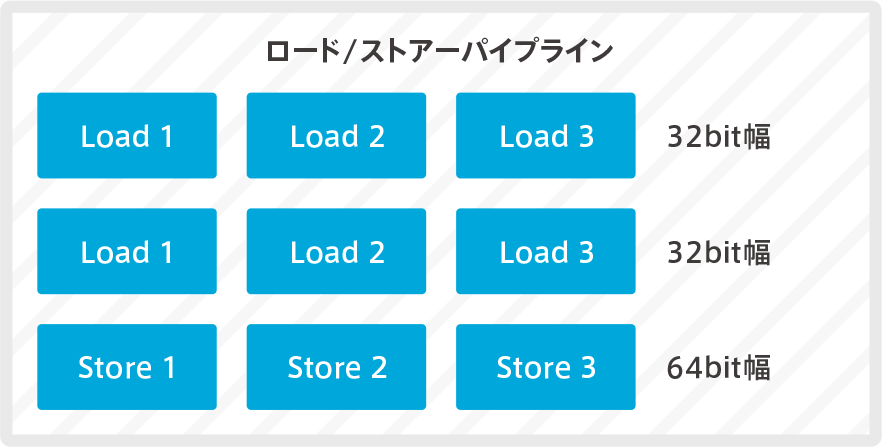
Load/store pipeline
A pipeline for load/store processing. It is handled by the Load and Store Unit (LSU) as described in the “Block Diagram (see Part 1)” chapter.
It is a dual 32-bit load channel (combined and 64-bit load channel), so it is a two-way execution pipeline.Dual issue of 32 bits (Issue), TCM and AXIM (64 bits load width) and dual 32 bits load capability and load into D-cache. The single 32-bit load channel is for the AHB interface.
The store channel is 1 channel of 64-bit, so this is also a 2-way.There are two separate STBs (Store-Buffering) for TCM and a Quality of Service (QoS) for AHBP and AXIM.
Execution pipeline (branches)

branch destination prediction
Branch destination prediction is a prediction of whether a conditional branching will occur or not. When a conditional branch is established, the branch destination instruction must be fetched from the beginning, which is a major obstacle in a pipeline with many stages. So, anticipate in advance and minimize the damage of pipeline failures.
Branching prediction uses a cache indexed by the address of the branch instruction.
Branching
The Cortex-M7 is equipped with BTAC (Branch Target Address Cache) as a cache for efficient branch prediction (more on BTAC later).BTAC’s only function is cache, not actual branch prediction. Therefore, the process of conveying branch status and branch prediction information to BTAC is performed in parallel.
Instead of doing the actual branching, this is to update the information in the BTAC when the branch occurs. This information includes information about the type of branch and whether the branch prediction was successful or not.
Execution Pipeline (FPU)
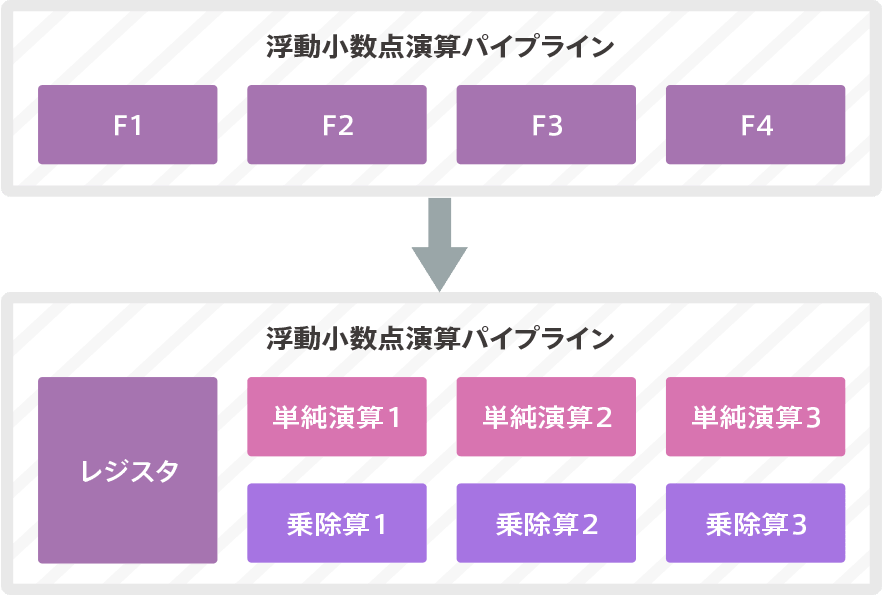
FPU
The pipeline is optimized for single precision (SP).The interior is physically divided into two pipelines: one is a simple arithmetic pipeline for addition, etc., and the other is an arithmetic pipeline for multiplication, division, etc. An individual pipeline can be assigned to either instruction slot.Also, in the case of sum-of-product operations on floating minority points (including fused Mac operations), the two pipes are connected and executed. Double precision operations are performed using a single precision pipeline and iterating through the stages.
In addition, the ALU pipe and the floating-point pipe are operated at different timing, so they can be executed in parallel with the ALU pipeline.
The FPU has an extended register file containing 32 single precision registers. These can be considered as follows.
- 16 64-bit double word registers, D0-D15
- 32 32-bit single word registers, S0-S31
This register file can be dynamically assigned to different pipelines as 4 read ports/2 write ports (32bit length).
The Cortex-M7 pipeline is basically in-order, but the relationship between the MAC and the floating minority point MAC is out-of-order.
Execution pipeline (instruction end)

Retire (exit process)
The Retire stage indicates instruction completion. This stage does not specifically affect the instruction; it updates the state visible to the programmer by the Retire stage. Therefore, the pipeline to the Retire stage is in a speculative (undetermined) state. In other words, if the branch prediction fails, the pipeline is discarded at the Retire stage.
The pipeline is also discarded when exception handling starts or when an instruction synchronization barrier instruction (ISB instruction (see Part 11 of Volume Cortex-A)), etc.
Execution pipeline (prefetch unit)

prefetch
There are pre-fetch cycles in the six-stage pipeline, although they are not counted. This process fetches up to 64bit instructions in a single cycle.There is a 4x64bit prefetch queue that separates instruction prefetching from the DPU pipeline. The prefetch unit (PFU) can read the data using the TCM interface. The address sends a request to the TCU or instruction cache controller, depending on the address.
If a branch occurs, a BTAC (see bottom) lookup is used for prefetching. That is, the branch information is returned from the BTAC.
When an interrupt occurs, the PFU performs vector loading and branching into vectors.
Execution Pipeline (Branch Target Address Cache)
Forecasting branching and branching speculation
As mentioned earlier, branch destination prediction is a prediction of whether or not a conditional branch will hold. It is a system that predicts in advance because the branch destination is not determined until the conditional branch instruction is completed.When a conditional branch is established, the branch destination instruction must be fetched from the beginning, which is a major obstacle in a pipeline with many stages. So, by anticipating ahead of time, we can reduce the damage of pipeline failures by a little bit.
Branching prediction is only a prediction, and it will either hit or miss, but the function that executes the instruction whether it hits or misses is called branching speculation.
Branching predictions can be dynamic or static. Dynamic prediction is a method of predicting the behavior of branch instructions while watching the behavior of the branch instruction, using the Branch Target Address Cache (BTAC), Branch History Table (BHT), and Branch Target Buffer (BTB) caches that index the address of the branch instruction.Static prediction is a method of predicting whether or not a branch will branch based solely on the contents of the branch instruction, or, in more complex cases, based on information (such as hint bits) provided by the compiler to the branch instruction.
In order to predict the branch destination address in the Cortex-M7, a cache BTAC that stores the branch destination address of the branch instruction is used, and the BTAC is accessed in parallel with the branch prediction function to predict it.
BTAC(Branch Target Address Cache)
A BTAC is a cache that stores the address of the branch instruction’s destination, sometimes referred to as a Branch Target Buffer (BTB). It is used in conjunction with the aforementioned branch pipeline (branch prediction function). A speculative prefetch is made from the branch target.
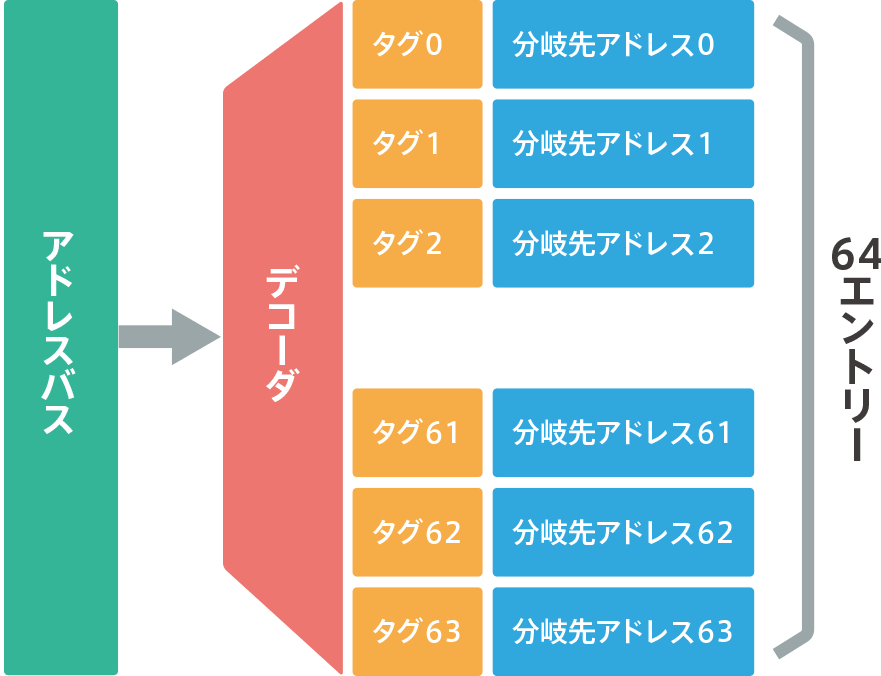
BTAC is a cache that accesses instruction addresses as indexes. Only the address of the conditional branch is memorized. The core accesses the BTAC in parallel with the branch prediction and starts instruction fetching with the address read from the BTAC as the next address without waiting for the branch instruction to be completed.It also depends on the number of BTAC entries (64 for Cortex-M7), but if the branch prediction is correct and the BTAC is hit, then the correct branch address will be issued with a relatively high probability. In order to eliminate the waste of instruction fetching, the BTAC uses a tag-matching method to determine whether a BTAC is hit or missed.
Cortex-M7 branching prediction
Using 64 entries of BATC (see image below) for branch prediction, the BTAC is executed in one cycle.If BTAC is not specified, static branch prediction is performed.
Execution pipeline (number of branch divisions)
Type of brunch
There are different types of branches, depending on the means of addressing the end of the branch.
- Direct Branching: Offset value determines branch destination
- Register Branches: Branch destination is determined by register value
- Loaded branches: the loaded value determines the branch destination
direct branch
This is a branch instruction whose branch destination is determined by the offset from the program counter value. When an instruction is issued (Issue), the address becomes valid.
register branch
This is a register indirect branch where the value stored in the register becomes the branch destination. In this case, the branch destination cannot be determined until the register is read, so it is difficult (or impossible) to predict the branch destination at the time of the decode or issue cycle.
However, in general, when a register indirect branch is used, it is a return from a sub-routine (in C language, a return from a function).When the subroutine (function) is called, the address is stored in R14 (LR) and split; R14 (LR) will be stacked, so when you return from the subroutine, if you return with the value of R14 (LR), you can easily return. In other words, branch prediction is easy to do. Not all subroutines, however, apply to this case.
roadside branch
The value loaded in the load pipeline determines the branch destination.

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …