





パイプラインの概要
パイプラインについては、第4回〜5回で詳細に説明いたしますが、Cortex-M3/4からの大きな変更点ですので、最初に簡単に説明します。
デュアルの6段スーパースカラパイプライン
デュアルのスーパースカラなので、ALUが2つあります。コードを64bitでフェッチしてきて、2命令を同時にデコードして、デコードした結果を、2つのALUに発行します。そして同時実行します。そのため、前述した様にCoreMarkもDMIPSもCortex-M4の2倍近い演算能力になっています。残念ながら、同時にデコードされた2つの命令の関係で、同時実行ができない場合があるため、完全に2倍にはなりませんが、それでも高性能には変わりありません。(一般的にはデュアルのスーパースカラはシングルパイプラインの1.6倍のパフォーマンスと言われています。)
命令発行パイプライン(フェッチ~デコード処理)
フェッチからデコードして、命令を判別するまでは3段のパイプライン処理です。デコード処理が2段になっていて、最初のデコードはDecodeと呼んでいますが、2つ目のデコードはIssue(発行)と呼ばれています。 Decodeした命令を、後段の実行パイプラインにIssueします。
実行パイプライン
論理演算(シフト含)と算術演算はALUが実行しますが、その他の実行は専用のパイプラインが用意されていて、別のハードウエアが実行します。デコードされた命令の種類によって各パイプラインへ振り分けられます。ロード/ストア実行はロード/ストアパイプラン、複雑な積和演算等はMacパイプライン、浮動小数点演算は浮動小数点演算パイプラインです。これらのハードウエアが並列処理を行います。
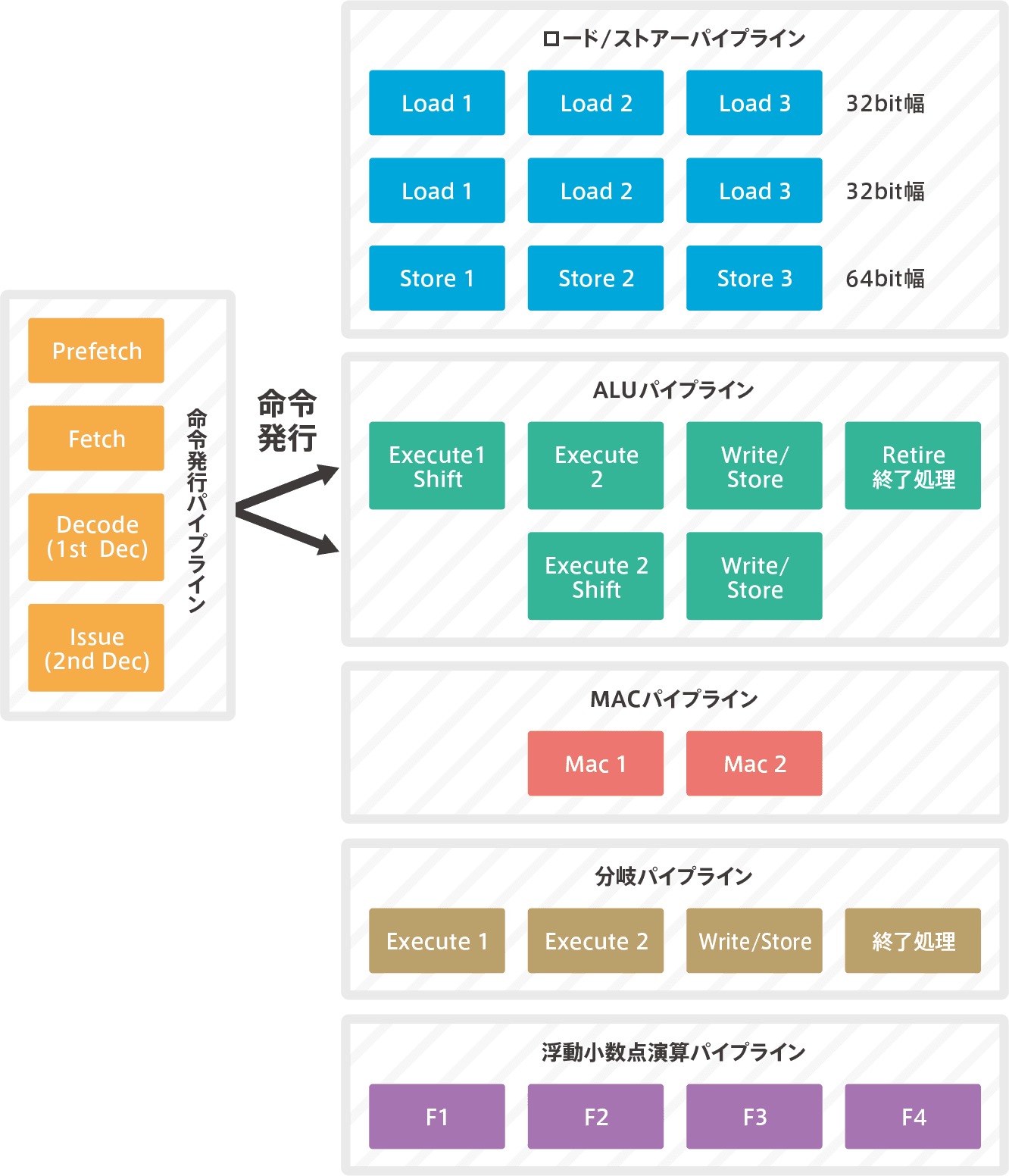
【Cortex-M7のパイプライン】
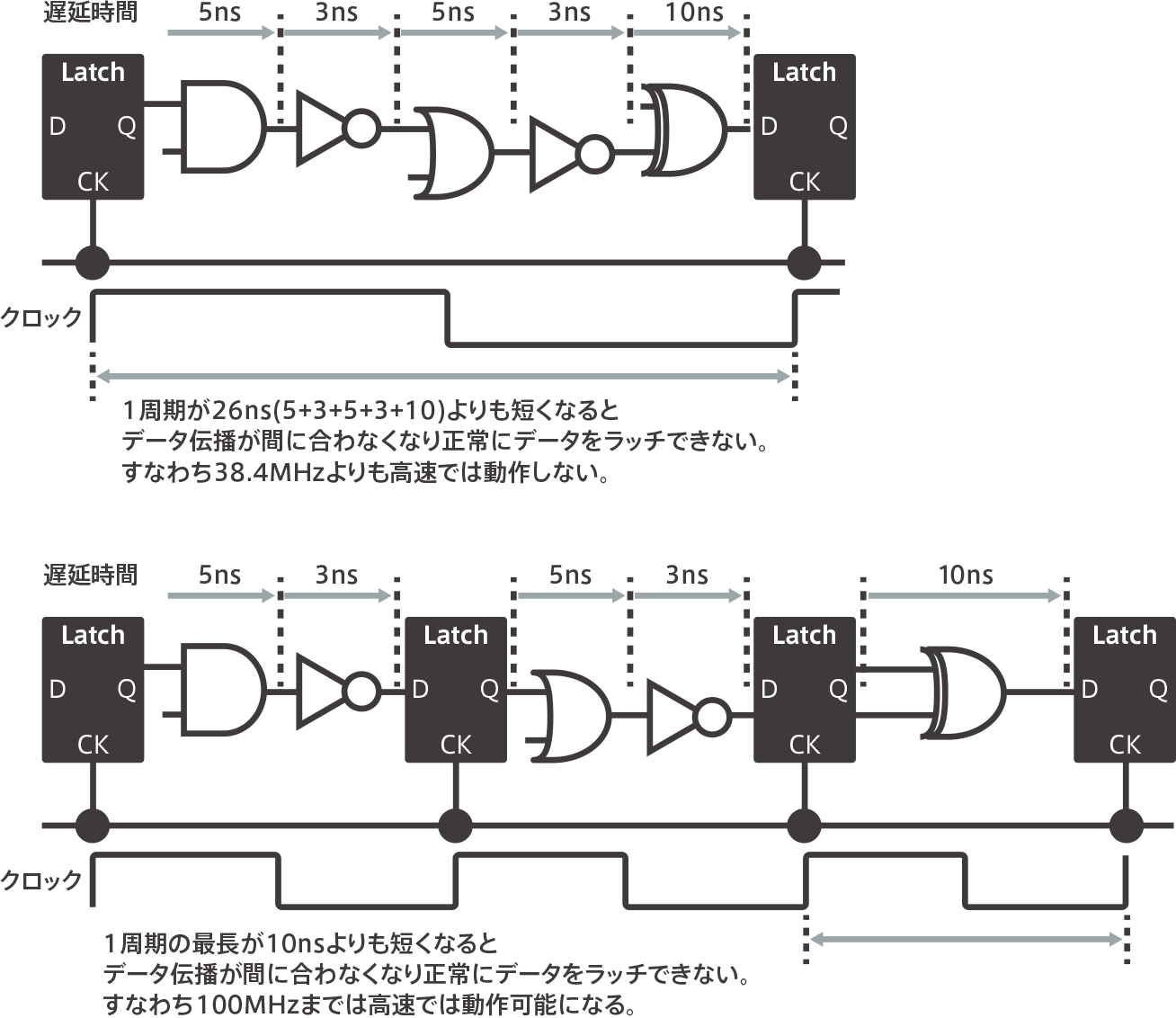
パイプラインの段数を増やすと、高速処理が可能になる理由
Cortex-M3/M4では3段パイプラインでしたが、Cortex-M7では6段に増えています。これは、動作周波数を高速にして性能を向上させるための工夫です。そこで、パイプラインの段数を増やすと、なぜ高速処理が可能になるかを簡単に説明します。パイプライン1段につき1クロックで処理されます。下図上が1クロックで処理する論理回路の例です。各論理ゲートの遅延時間を全部足すと26nsになります。したがって38.4MHz以上のクロックだと処理が間に合いません。必然的に、このマイコンの動作周波数の最大は38.4MHzになります。ところが、下図下では同じ処理を3段に分割しました。いわゆる3段パプイラインの模擬図になります。最も遅延の時間の大きいところで10nsです。したがって、100MHzのクロックまでは動作できるということです。パイプライン処理は段数が増えても実質1クロック1命令の処理が可能です。したがって、段数を増やすと高速処理が可能になるという訳です。(Cortex-M編 第10回参照)
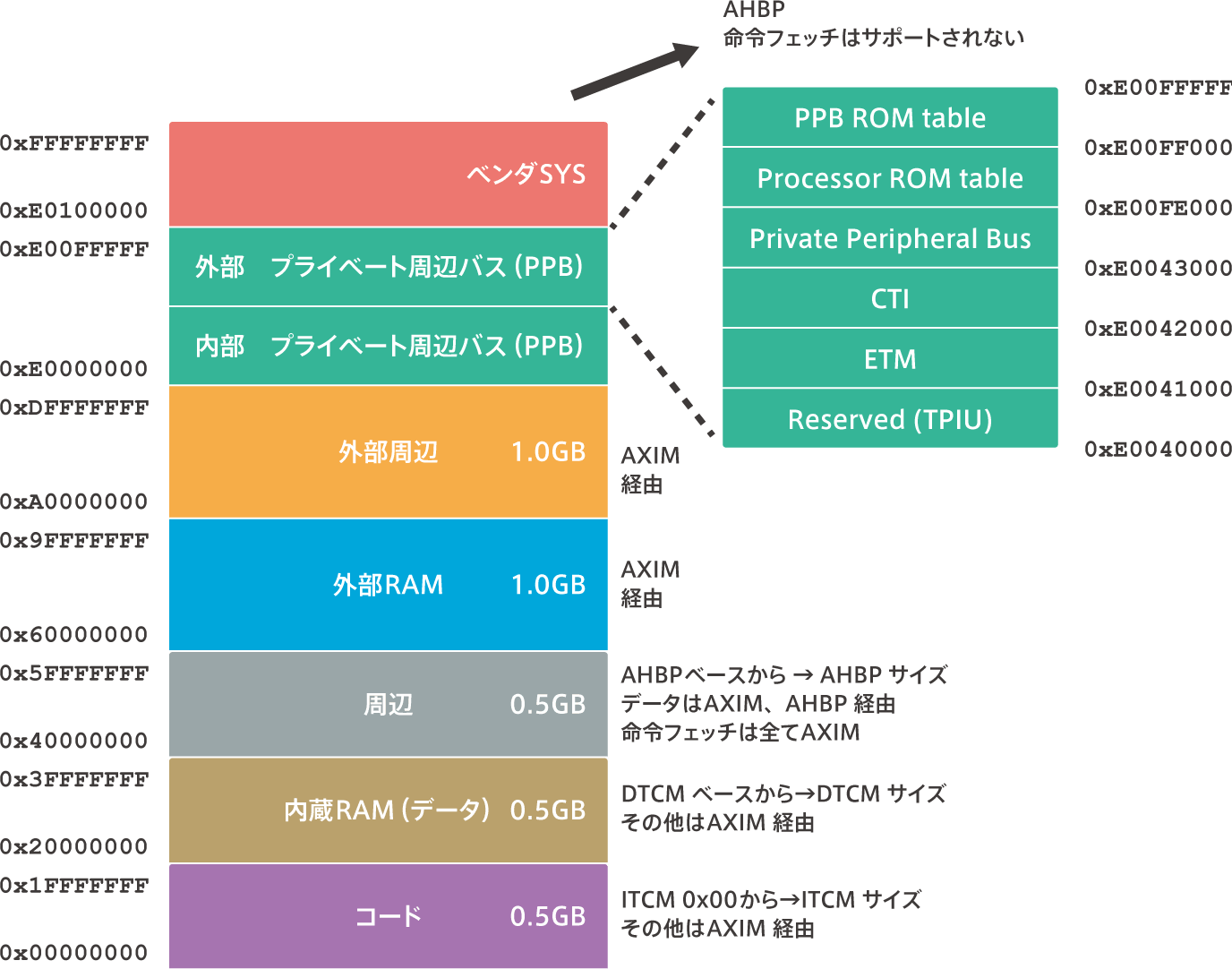
メモリマップ
メモリマップの概要

【Cortex-M7のバスインターフェース】
Cortex-M7のメモリマップはCortex-M3/M4と変りません。しかし、 Cortex-M3/M4のインターフェースはI-Bus、D-Bus、S-busだけだったのに対しCortex-M7には、AXIM、ITCM 、DTCM 、 AHBP、 EPPBのバスインターフェースが存在します。Cortex-M7では、メモリマップの領域ごとに接続されているバスインターフェースが異なります。例えば、コード領域に設けられた内蔵Flashから命令をフェッチするのと、外部メモリに格納されている命令をフェッチするのでは、バスインターフェースが異なります。前者はITCMまたはAXIM経由、後者はAXIM経由のみになります。(バスの名前はAXIですが、マスターとなってAXIを制御するハードをAXIMと呼びます。MはMasterのM。)
コード領域
通常この領域には命令コードを格納している内蔵メモリ(Flash、RAM)が接続されるようになっています。そして、バスインターフェースはAXIMとITCMに接続されています。ITCMのIは命令(Instruction)の意味です。0x00000000 番地から始まり、実際に内蔵されている内蔵メモリの大きさの分だけ存在します。最大で0.5GBです。
内蔵RAM(データ)領域
通常この領域にはデータを格納している内蔵メモリ(Flash、RAM)が接続されるようになっています。そして、バスインターフェースはAXIMとDTCMに接続されています。DTCMのDはデータ(data)の意味です。0x20000000番地から始まり、実際に内蔵されているメモリの大きさの分だけ存在します。最大で0.5GBです。
周辺領域メモリマップ
周辺機能のレジスタ等を配置する領域です。UARTやタイマ、USB、Ethernetなどがマッピングされています。バスインターフェースはAXIMとAHBPに接続されています。データアクセスの場合はAXIMまたはAHBP経由ですが、命令フェッチはAXIM経由のみになります。0x40000000番地から始まり、実際に内蔵されている周辺機能のレジスタ領域の大きさの分だけ存在します。最大で0.5GBです。
外部RAM領域
外部RAM(メモリ)用の領域です。命令フェッチとデータアクセスはAXIM経由で行われます。0x60000000番地から始まり、実装されている外部メモリ領域の大きさの分だけ存在します。最大で1.0GBです。
外部周辺領域
外部周辺機能用の領域です。命令フェッチとデータアクセスはAXIM経由で行われます。0xA0000000番地から始まり、実装されている外部周辺機能領域の大きさの分だけ存在します。最大で1.0GBです。
プライベート周辺バス領域
プロセッサの外部周辺機能のレジスタが配置される領域です。ここのレジスターへのデータアクセスは、EPPB経由で行われます。この領域はExecute Never(XN)です。これは「命令フェッチは禁止されている」と言う意味です。0xE0000000番地から始まり、実装されているレジスタ領域の大きさの分だけ存在します。
- 内部PPB 以下の機能にアクセスを提供します
- ● ITM(Instrumentation Trace Macrocell)
- ● DWT(Data Watchpoint and Trace)
- ● FPB(Breakpoint unit)
- ● SCS(System Control Space :MPU含)、命令キャッシュとデータキャッシュと統合ネスト型ベクタ割り込みコントローラ(NVIC)、システムタイマ(Systick)
- ● プロセッサーとPPB ROMテーブル
- 外部PPB 以下の機能にアクセスを提供します
- ● ETM(Embedded Trace Macrocell)
- ● CTI(Cross Trigger Interface)
- ● 外部のシステムでのCoreSightデバッグとトレースコンポーネント
ベンダSYS領域
ベンダシステム周辺装置のためのシステムセグメントです。データアクセスはAHBPインタフェース経由で行われます。この領域はXNであり、命令フェッチは禁止されています。0xE0100000 番地から始まります。
32bitデータ境界におけるアンアラインドアクセスの取り扱い
Cortex-M7プロセッサはアンアラインドアクセス(Cortex-M編 第8回参照)をサポートしています。すべてのアクセスは見かけ上シングルサイクルで実行されます。しかし、内部で、それらが、2回以上のアラインドアクセスに変換されて実行されます。 従って、アラインドアクセスよりも遅くなります。加えて、いくつかのメモリ領域(PPB等)ではアンアラインドアクセスはサポートされていません。そのためArmではアラインドアクセスを使うように推奨しています。予測しないアンアラインドアクセスが発生した場合は、コンフィギュレーションコントロールレジスターの「UN ALIGN_TRP-bit」をチェックすればわかります。
あわせて読みたい

また、アンアラインドアクセスが使えるのは次の命令に限られます。
- LDR, LDRT
- LDRH, LDRHT
- LDRSH, LDRSHT
- STR, STRT
- STRH, STRHT
この他のロード・ストア命令では例外処理が発生します(UsageFault)。便利な機能ですが、使用する際には注意が必要です。

こちらも是非



“もっと見る” Cortex-M7編

電力管理、コアデバッグ、浮動小数点ユニット
Cortex-M7もCortex-M3/M4と同じように低消費電力モードをサポートしています。基本はCortex-M3/M4と同じです。Cortex-M7にはWIC(ウェイクアップ割り込みコントローラ)を含むと3種類のスリープを持っていることになります。
AXI転送
AXI転送を行う際には、次に示す制限があります。バーストは、最大32バイト。バースト長さは、最大4転送。Strongly-orderedメモリまたはDeviceメモリの書き込みバーストの最大長は2転送です。Strongly-orderedメモリまたはDeviceメモリの読み出しは、常に1転送です。
キャッシュの初期化と有効化
Cortex-Aで採用されているユニフィケーションのポイント(Point of unification:PoU)と一貫性のポイント(Point of coherency :PoC)の考え方がCortex-M7でも採用されています。