





組み込みソフトウェア開発をする前に
リアルタイムOSを使った組み込みソフトウェア開発を行う際、覚えておいたほうがよい「4つの心得」を紹介しましょう。
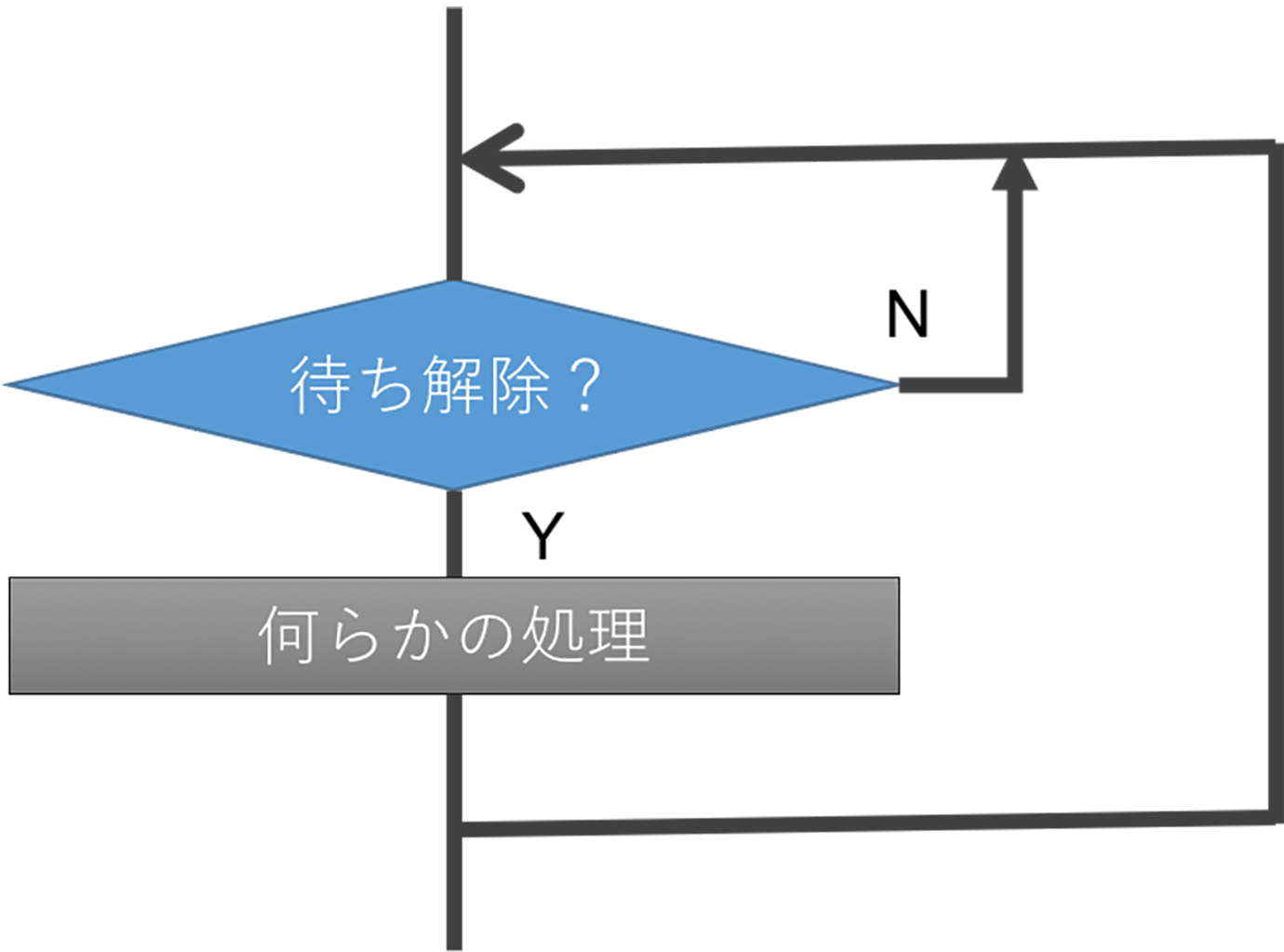
心得 其の1「タスクは、ループの中で待ちを作る」
RTOSなどのタスク関連の資料を見ると、必ずループ処理になっています。これは、処理を単純化したものを繰り返し処理を行うためであり、1回限りの処理にタスクを消費することはほとんどありません。無駄なメモリを使ってしまうだけで、メリットはありません。なので、タスク内で、無限ループ処理を作ります。その中に、「待ち」と呼ばれる処理を入れることで、スケジューリングや同期を取る方法が確立できます。具体的な「待ち」は、rcv_xxxx()、wai_xxxx()などのAPIを使用するということです。「待ち」の間に、他の制御ができるため、とても効率がいいのです。
これをリアルタイムOSがない環境で実装すると、ただ待ってしまい、他の処理も止まったままになってしまいます。これでは、CPUのパワーが無駄になるだけです。
心得 其の2「割り込み処理内は、最小限のコードで」
組み込みシステムは、割り込み処理を活用することも多く、割り込みに頼ってしまうことや、割り込み処理をきっかけに、処理がスケジューリングされることもあります。だからと言って、割り込み処理の中であまりに多くの処理をしてしまうと、割り込み処理中に次の割り込み要求が来きてしまいます。そうなると、割り込み処理が多重化し、遅延が発生し、「ジッター」と呼ばれる不規則な遅延処理が積み重なり、組み込みシステムの品質低下を招きます。そうならないようにするためにも、割り込み処理の中では必要最低限の処理に留めておくべきです。どうしても間に合わない場合は、設計の段階で何か間違っていると言えます。手遅れにならないように、もう一度システム構成やソフトウェア設計を見直してみましょう。
あわせて読みたい
心得 其の3「大きなデータは、ポインタで渡す」
これは組み込みシステムに限った話ではないですが、大きなデータをコピーしてから渡すと、その分処理時間が必要になります。DMAなどハードウェアリソースを活用することで、CPUによるデータコピーの手間を減らすことができます。さらに、DMAを併用するとCPUとは別プロセスで動いてくれるので、限られたリソースで動かす組み込みシステムにとっては、昔から使われているテクニックの一つです。特に、画像のデータやパケット通信のペイロードデータは、ポインタ渡しをすることで、「ゼロコピー」となり、データ処理が速くなるメリットがあり、様々な場面で使用されているテクニックです。
大きなデータの同期には、RTOSが提供している機能「メッセージバッファ」や「メールボックス」を使用すると、ハードウェア依存が低減します。小さいデータの場合は、データキューというリングバッファの仕組みもあります。リアルタイムOSによって、提供していない場合もあります。
あわせて読みたい
心得 其の4「時間のボトルネックを見極める」
組み込みシステムでは、時間的な制約がついて回ることが多いものです。「1ms以内に、これらの処理を終わらせないといけない」ことや「この処理の10秒後に次の処理を実行する」などです。1msに終わらせなければいけない処理が、1msピッタリであれば、仕様は満たせているように見えますが、余裕はありません。少しでも遅延が発生すると、心得その1で記載したように、ジッターが発生します。この問題は、必ず回避しないといけません。回避できない場合は、そもそもの設計に誤りがあると言えます。なので、少しでも多くの待ち時間を増やすことで、他の処理を実行することができるように設計を見直しましょう。

こちらも是非



“もっと見る” RTOS編

Toppers/ASP3の使い方
SOLID-OSによる割り込みは、Toppers/ASP3がベースになっており、カーネルの管理下で割り込みの処理を行いますので、「割り込みサービスルーチン(ISR)」または「管理内割り込み」と呼んだりします。それ以外のものは、「割り込みハンドラ」もしくは「カーネル管理外割り込み」と呼びます。
組み込みOSに最適なのは?リアルタイムOSとLinuxの違い
組み込みシステムの構成を考えていく上で、どのOSを採用するかは、開発初期段階においてとても重要です。一般的には、時間的制約があるシステムの場合はリアルタイムOSが、ネットワークやファイルシステム、高度なグラフィカル表示が必要な場合はLinuxが向いていると言われています。
割り込み
割り込みは、タスクとは独立して実行される処理です。そこで、T-Kernelにおける割り込みの利用方法に加えて、実行時のコンテキストの違いから生じる動作の違い、割り込みハンドラの作成方法や動作の詳細を説明します。