





Before you do embedded software development
Here are four tips you should keep in mind when developing embedded software using a real-time OS.
Headfulness #1: “Tasks create a wait in a loop”
If you look at RTOS and other task-related materials, you will always find that the process is a looping process. This is because the process is simplified and repeated and rarely consumes a task for a one-time operation. It just wastes memory and has no benefit. So, within a task, we create an infinite loop process. By putting a process called “waiting” into it, we can establish a method of scheduling and synchronization. Specifically, “waiting” means using APIs such as rcv_xxxx(), wai_xxxx(). It’s very efficient because you can do other controls while you’re “waiting”.
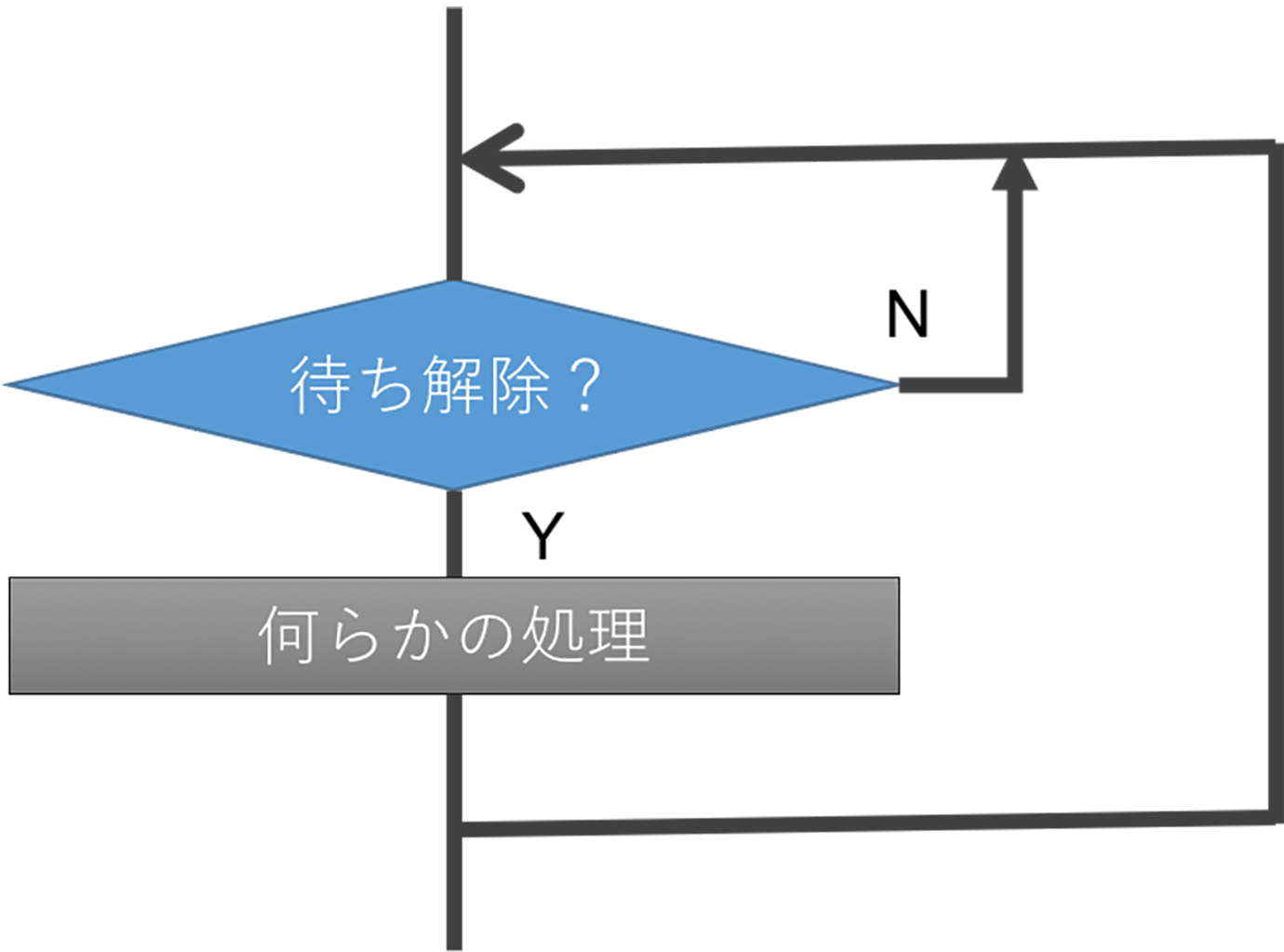
If you implement this in an environment where there is no real time OS, you will just wait and other processes will remain static. This is just a waste of CPU power.
Tips #2 “Use the least amount of code in interrupt processing”
Embedded systems often make use of interrupt processing, and sometimes they rely on interrupts, and sometimes the interrupt processing is the trigger for scheduling processes. However, if too many interrupts are processed in the interrupt processing, the next interrupt request will come while the interrupt is being processed. When this happens, the interrupt processing becomes multiplexed, causing delays and irregular delays, known as “jitter,” to pile up, leading to a decrease in the quality of the embedded system. To prevent this from happening, the interrupt processing should be kept to the minimum necessary. If you can’t do it in time, something is wrong in the design process. Let’s review the system configuration and software design again to make sure it’s not too late.
Read
Knowledge #3 “Passing large data by pointer”
By utilizing hardware resources such as DMA, it is possible to reduce the amount of time and effort required to copy data from the CPU. Furthermore, when used in conjunction with DMA, it runs in a separate process from the CPU, so it is one of the techniques that have been used for a long time for embedded systems that run on limited resources. Especially for image data and packet communication payload data, passing pointers has the advantage of “zero-copying” and speeding up data processing, which is a technique used in various situations.
For large data synchronization, the hardware dependency can be reduced by using the “message buffer” and “mailbox” features provided by RTOS. For smaller data, there is also a ring buffer mechanism called a data queue. Some real-time operating systems do not offer this feature.
Read
Headfulness, Part 4: “Identifying the Time Bottleneck”
In embedded systems, time constraints often follow. If the process that must be completed within 1ms is exactly 1ms, it may seem that the specification is met, but there is no margin for error. If there is even a small delay, jitter will occur as described in the first lesson. This problem must be avoided. If it cannot be avoided, then the design is faulty to begin with. So, rethink your design so that you can perform other processes by increasing the wait time as much as possible.

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …