





目次
About cache
Overview of the cache
As mentioned earlier, the Cortex-M7 has a Harvard cache (instruction and data caches).The size of the cache is optional for the microcontroller vendor, with instruction and data caches ranging from 4KB to 64KB each.You can choose not to mount it (size 0KB), but there is probably no such vendor.
The cache is configured to accompany AXIM, so instructions and data via TCM cannot be handled.If you want to include a cache in your TCM, your microcontroller vendor will need to incorporate it in their own architecture.
It is called L1 (primary) cache because it is installed in the core. If you want to include an L2 (secondary) cache, the AXIM can be controlled by the AXIM by following the Arm CoreLink L2C-310 Level 2 cache controller specification, which can be incorporated by the microcontroller vendor’s own and connected to the AXI interface.It is possible for a microcontroller vendor to implement its own L2 cache on shared memory, but in any case, consistency with the L1 cache is not supported.
The instruction cache is a two-way set-associative and the data cache is a four-way set-associative structure.The n-way set-associative is a method for selecting lines in the cache.The configuration is described in detail in each cache chapter.Both caches allow you to select ECC as a vendor option. Some products do not have the option selected, please refer to the product documentation.
To make it easier for users to maintain the cache, several registers are provided. These registers can be manipulated to enable/disable and clean the cache easily. Supported attributes are “write-through, no write allocation”, “write-back, no write allocation” and “write-back, with write allocation”. Please refer to Tidbits 5 for a description of each.
supplement
This is a bit off topic, but we talked about caches for TCM at the beginning.In fact, there are microcontrollers with Cortex-M7-based products that have a cache in the TCM.TCM has two types of memory, ITCM and DTCM, so it seems that instruction cache and data cache need to be built in to each of them, but the memory with slow access is Flash memory, and the memory connected to DTCM is assumed to be SRAM with fast read speed, so DTCM has no cache No need.
So data in Flash that is placed in an area accessed by ITCM will be slow to access? That’s not true.You can put an integrated instruction cache and data cache on the ITCM to retrieve data from the ITCM. On the other hand, you can put instructions in the DTCM’s SRAM and execute them without any problems, without a wait cycle.
Summary of the cache
- Harvard Architecture for optimal performance
- Individually configurable sizes for both instruction and data (4KB – 64KB each) (This is optional for microcontroller vendors. (This is optional for microcontroller vendors; the size of the package is specified in the microcontroller product’s manual).
- The cache is only in the AXIM region (TCM and AHBP are not supported)
- Instruction cache is two-way set-associative, data cache is four-way set-associative
- Includes extensions required for Armv7E-M system architecture
- Additional cache maintenance operations: register for cache maintenance
- System software is affected by the inclusion of a cache
- Full support for the following attributes
- write-through, no write allocation
- write-back, no write allocation
- write-back, with write allocation
- No support for hardware consistency
- When implementing the L2 cache on shared memory, consistency with L1 is not supported.
- ECC is optional (all cache ECCs are handled internally)
What is Cash?
I’m sure you already know this and it’s none of your business… You can use “large but slow memory” as the main memory and several times faster memory (this is called cache memory or cache) to store recently accessed instructions and data from the main memory in the cache, and the next time the same address is accessed, you can access the cache It is a method of speeding up data access by.
Meaning of L1 cache and L2 cache
The L in L1 stands for level (LeveL), sometimes called a primary cache. In general, it is called L1 (primary), L2 (secondary)… in order of closeness to the core. in the order of closest to the core, we call it L1 (1st order), L2 (2nd order)…If you can’t fit into the L1 cache, use the L2 cache, which is slower than the L1 cache, but has a larger capacity.The Cortex-M7 has a built-in L1 cache that accompanies AXIM.
Basic structure of the cache
Since the cache is a high-speed, small-capacity memory, it is built with the usual SRAM structure.The internals are divided into a tag section and a data section, and the tag section is used to determine whether you hit or missed the cache.The structure of the tag section can be divided into several methods.
The case of a single set of tags is called Direct Mapped. Since the structure is simple, it is easy to create, but the hit ratio is not as high as other methods. When multiple tags are used, it is called Set Associative.The higher the number of tags, the higher the cache hit rate, but the more difficult it becomes to create. If it is composed of n tags, we call it the n-way set-associative method.
The instruction cache of Coretx-M7 is a two-way set-associative and the data cache is a four-way set-associative structure.When an address is given, it is compared to all tags, which is called a Full Associative system.It has the best hit rate, but is not usually used because of its high cost.
cache hit
If the target instruction or data exists in the cache.
cash miss
If the target instruction or data does not exist in the cache.
line fill
A read request on the bus for the entire cache line. A fill is to read the contents of main memory into the cache in the event of a cache miss. This line, once enabled, is then allocated to the cache.
Eviction
When the cache is full, store the data you need in the cache and kick out the data you don’t need.
Write through
A method in which the CPU writes data to the cache and simultaneously writes the same data to the main memory.
Write-back
When the CPU writes data to the cache, it only writes to the cache until the cache is full, and then writes the ejected data to main memory when the cache blocks are ejected.
Cortex-A, Part 9 also explains the above terms in detail, please refer to it.
Cache Features
Overview
Cache has a long history, and many different architectures have been considered since before Arm was created.The book I have on microcontroller architecture (1982 edition) explains various methods.The point is how to determine if the cache is hit or miss and how to find the data when a hit occurs. In the case of a hit, you must quickly find out where the hit data is located in the cache. The cache is useless unless the process of finding the data after a hit is performed in one cycle.
There are three typical modern methods. This article is not a description of microcontroller architecture, so I won’t go into detail, but the following are some of the most common, based on data retrieval methods.
Direct Mapped
It is a method to specify one line for each address. The feature is that the internal structure is easy to create.
Set Associative
This is a list of several Direct Mapped.A sequence of n pieces is called the n-way set-associative.With n tags, you can get a higher hit rate than Direct Mapped.The higher the number of n, the higher the hit rate, but there is a trade-off with circuit size, so the optimal n is selected for each product.
Fully Associative
This method compares an address to all lines. If the number of lines is the same, the hit rate is higher than the other methods, but it has the disadvantage of requiring a larger internal circuit.
Cortex-M7 cache
The instruction cache is based on the two-way set-associative scheme. This method has a relatively small circuit size, and its performance is not much worse than four-way set-associative.
The data cache is a four-way set-associative system. Supports dual-issue loading without the use of dual-port memory.It has a 32-entry, four-way set-associative structure that is updated on major cache hits and new allocations.
Both caches support ECC, but it’s optional, so check the product documentation to see if they support it.
Instruction cache two-way set-associative
Overview
The instruction cache of Cortex-M7 is a two-way set-associative configuration, as shown in the figure below. In this example, the instruction cache is 16KB, one line is 32 bytes, so two-ways x 256 lines x 32 bytes = 16KB.Since it’s a two-way, there are two tag comparators that decode the tag portion of an address and compare the tag portion output of a fixed tag portion at the same time, and if there’s a match, it’s a hit.
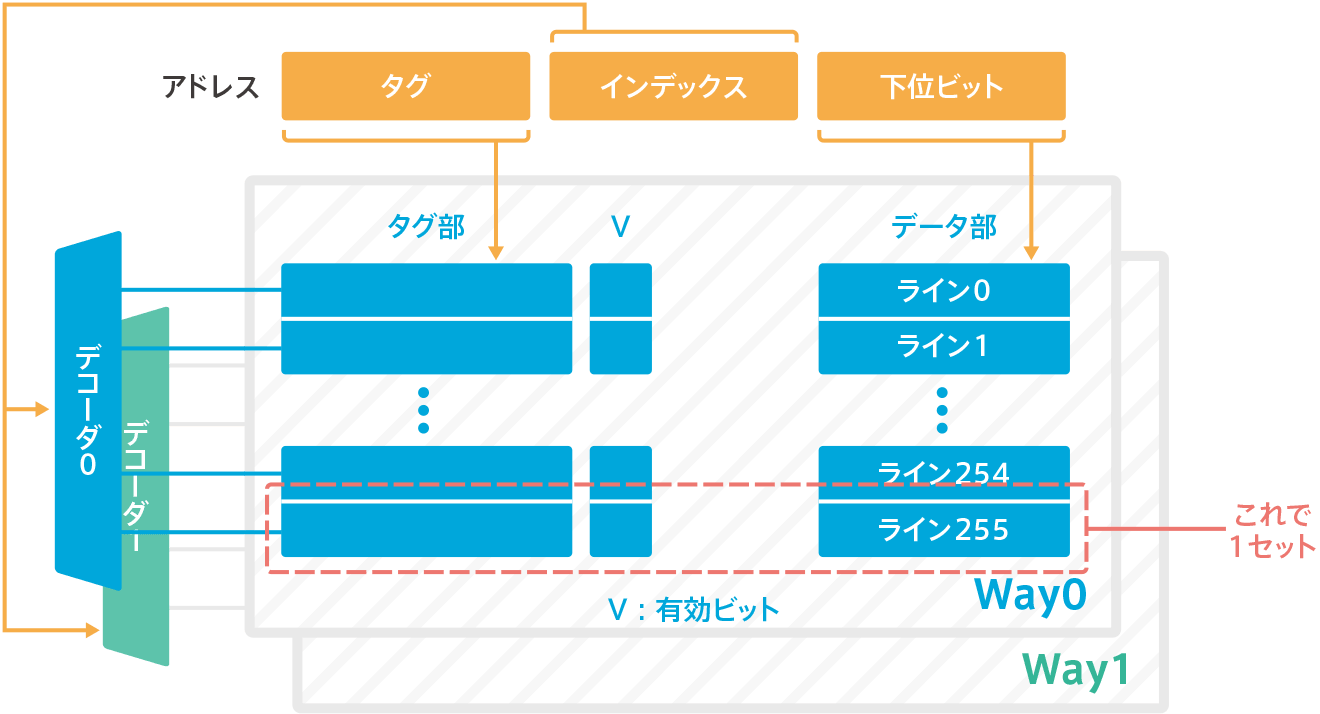
cache RAM
The two words “cache” and “cache RAM” are used interchangeably in the Cortex-M7 manual. Cache” refers to the entire cache and “cache RAM” refers to the portion of RAM in the cache. The term “cache RAM” is used to describe the inner workings of the cache.
The cache RAM consists of a tag section and a data section.The tag section is 4x(22+7) bits without ECC, and with ECC, it is 4x(22+7) bits, since it is 7 more bits of ECC.The data section is 4×64 bits without ECC, and with ECC, it is 4x(64+8) bits, an increase of 8 bits of ECC.
The tag part and the data part are called a set. In the case of the above diagram, it is a two-way set of 256 sets.The tag section contains the tag, index, tag value, outter attributes and valid bits (only valid bits are shown in the figure above). The data part, as the name implies, is data.
| RAM | ECC-free | With ECC |
|---|---|---|
| tag section | 4×22 bits | 4x (22+7) bits |
| data section | 4×64 bit | 4x (64+8) bits |
error recovery
When the Cortex-M7 processor detects an error in the RAM in the cache, it can be recovered by performing a clean, disable, and retry operation. After the clean and deactivation operations are completed, the retry access is performed.
In the instruction cache, the line is always clean (the data in main memory and the cache match), so you only need to disable the line. The correct value is fetched from external memory by retry access. On the other hand, you can optionally add ECC. This is used for single-bit error correction; more on ECC in the chapter on ECC.
Data Cache Four-way Set Associative
Overview
The Cortex-M7’s data cache is a four-way set-associative configuration, so it will look like the following figure. Since this is a four-way set, it has four tag comparators to decode the tag portion of the address and compare the output of the fixed tag portion simultaneously. This is the case.
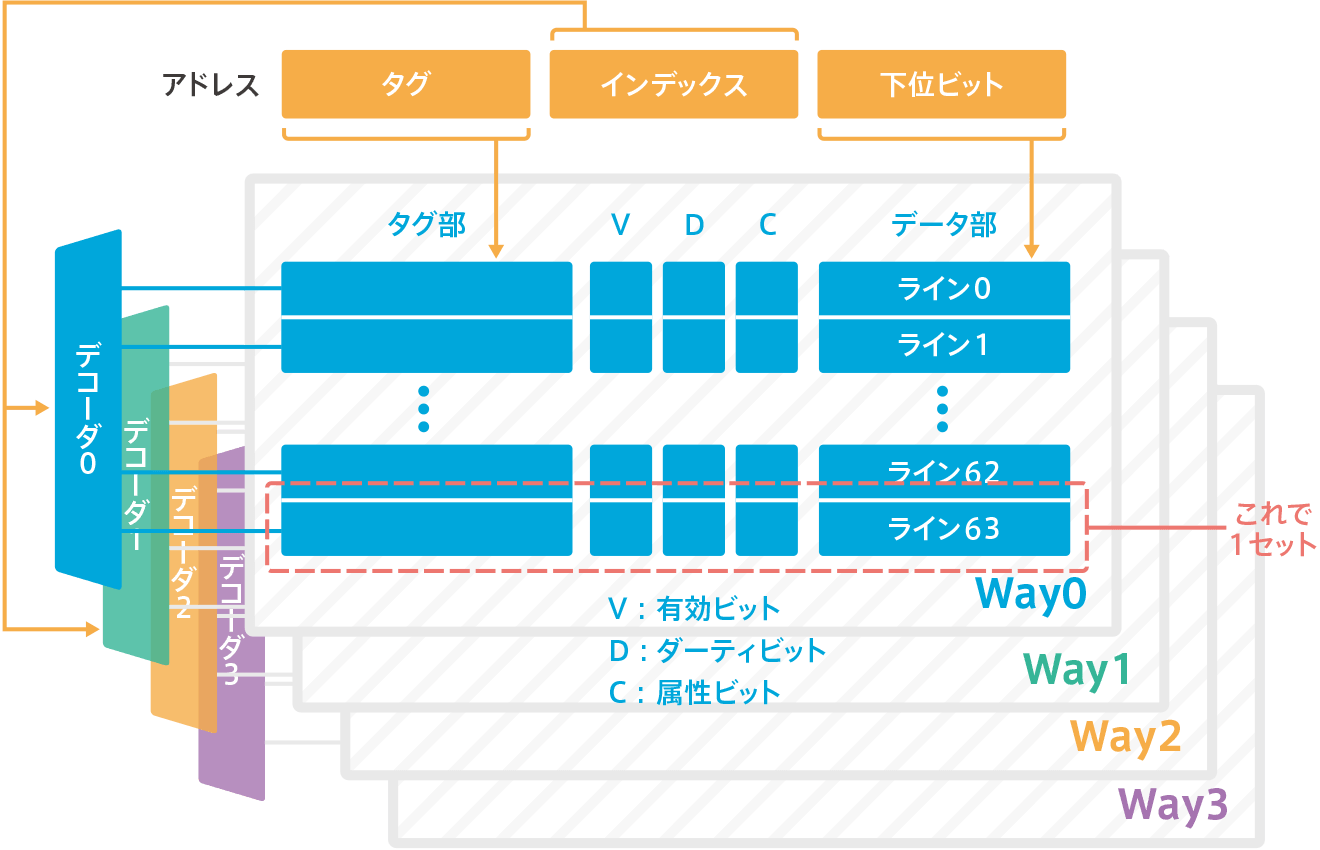
cache RAM
The cache RAM for the data cache also consists of a tag section and a data section. The tag section is 4×26 bits without ECC, or with ECC, it is 4x(26+7) bits with an additional 7 bits of ECC. The data section is 8×32 bits without ECC, or with ECC, it is 8x(32+7) bits with 7 more bits of ECC. The tag section contains the tag, index, tag value, outter attributes (described by C in the diagram above), valid bits and dirty bits (described by V, D, and C in the diagram above).
| RAM | ECC-free | With ECC | |
|---|---|---|---|
| Tag section | 4×26 bits | 4x (26+7) bits | |
| Data part | 8×32 bit | 8x(32+7) bits |
Dirty bit
When the memory is write-back (WB), it does not reflect the data written to the cache to main memory every time, but only updates the cache. So when that line is evicted, it writes back to main memory to get the match. Then, for a certain period of time, the data in main memory and cache do not match. So it marks the cache line as dirty and sets up a dirty bit on the tag memory to manage whether the data matches the main memory data or not.
Recovering errors
In data caches, cache lines can get dirty; RAM correction operations are done as part of the clean and disable operations for the cache. This happens in the write buffer and the corrected data is written back to external memory. The access is retried and the correct value is read from external memory. If the data cannot be corrected then the error is irreparable.
Caches and memory attributes
Attribute
Memory attributes are set per memory region by default but can be defined by the user via MPU (MPU_RASR: MPU Region Attribute and Size Register). These attributes affect the behavior of the AXIM/cache memory system.
Memory Type
There are three types of memory, which we discussed in Part 6, Trivia 4.
Strongly Ordered
A memory type that executes Load and Store in the order written in the program. (e.g., an external private peripheral bus ROM table area)
Device
Load, Store is a type of execution that has side effects. Do not speculative execution or repeat the same action. (e.g., external peripheral regions).
Normal
Normal memory type. Read multiple times and the value is the same, or write the same value multiple times and the result is the same. (e.g., the MCU’s internal RAM)
Shared/Non-Shared and Exclusive Access
(*) Unless CACR.SIWT is set to 1.
The store buffer can merge several stores into Normal memory if the store instruction does not access an exclusive store instruction to a memory area marked as Shared.
Only non-cached Shared exclusive transactions are marked as exclusive external interfaces; if CACR.SIWT is 1, then a load/store exclusive instruction to a cacheable memory region of Shared is an exclusive access on an external interface This is not the result of this.
On the other hand, only Normal memory is considered to be restartable. In other words, in the case of a compound word transfer, when an interrupt occurs, the transfer is interrupted and restarted after the interruption is processed. In this case, only the built-in exclusive monitor is updated and checked for exclusive access to the non-shared memory. In addition to using the built-in monitor, if desired, an external monitor using the external memory interface AXIM or AHBP can also be used to check for exclusive access to shared memory.

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …