





History of Arm
The Birth of Arm
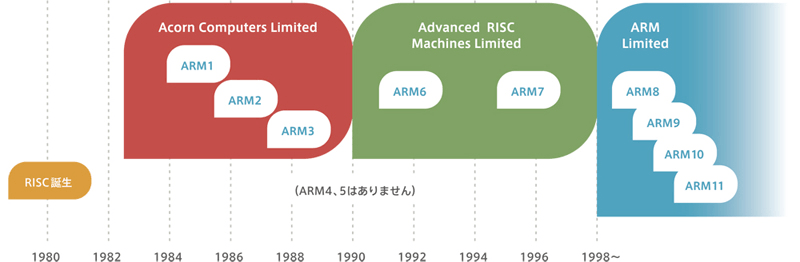
Arm was initially (around 1983-85) developed at Acorn Computers Limited in Cambridge, England. It is the first RISC microprocessor to be commercially developed.In 1990, Advanced RISC Machines Limited was established to expand the use of Arm technology. Since then, Arm has been licensed to many semiconductor manufacturers around the world.
According to an engineer who was working at Acorn Computers Limited at the time, The announcement of the formation of Advanced RISC Machines Limited was not immediately followed by an understanding of what had happened.Anyway, he said he felt “like something big has changed.Over time, he said, he was able to grasp the reality.
The RISC microprocessor, which I will explain in more detail later, is simply put, “The actions executed by a single instruction are simple, but they are combined to execute a series of actions efficiently in order to make them fast.” It is a processor based on the theory that.He was born around 1980 in a research program at Stanford University and the University of California, Berkeley.There were pros and cons to the RISC processor at the time, but Arm was developed about five years after the RISC processor was announced, so it was a surprisingly quick response.
Arm 1 to 3 were developed during the Acorn Computers Limited era.The first product to become an Advanced RISC Machines Limited is the Arm6.This was followed by the development of the Arm7, which was in high demand in mobile phones.So the de facto starting product for Arm is said to be Arm7.Later, while improving the functionality Arm8, Arm9, Arm10 and Arm11 were rolled out in quick succession.
Arm cores are developed not only for function, but also for cost and low power consumption.As a result, it offers users the advantage of being less expensive and consuming less power than other cores of the same performance.
Arm’s Business Model
Arm doesn’t make semiconductor products. Therefore, we do not sell them.
We design the CPU IP, license the IP to a semiconductor supplier, and the contracted semiconductor manufacturer manufactures and sells the product.You then pay Arm a license fee for the original IP and a royalty on each chip or wafer you manufacture.The world’s leading semiconductor and systems companies have signed licensing agreements with Arm.The network is then configured as a partner of Arm.
Today, there are more than 900 partners, with more than 25 billion processors manufactured and more than 16 million shipped per day.These numbers are a clear indication that Arm is the world’s standard CPU.Interestingly, even semiconductor manufacturers that only make their own cores (from Arm’s point of view, they are a competitor) have There are many manufacturers that have Arm licenses.
If you look at Arm’s homepage, you will find a list of the semiconductor manufacturers that have Arm’s license, so we recommend you to look at them. You’d be surprised at the sheer number of them.
Arm was an unidentified CPU at first.
Arm cannot do business without a licensing agreement with a company that manufactures semiconductors.In the early days of the company’s existence, we made sales pitches to major semiconductor manufacturers around the world.
I know an engineer who has actually dealt with Arm’s sales pitch.At the time, he was researching and designing CPU architecture in R&D for a major Korean semiconductor manufacturer.Suddenly, one day, Arm came and was surprised when asked if he would make a license contract.To be honest, he couldn’t believe such a company he didn’t know well, so he didn’t sign the contract after hearing the story.
He told me over a cup of makgeolli that he never thought it would spread around the world like it does now.
Arm’s Roadmap
Arm’s Classic Products
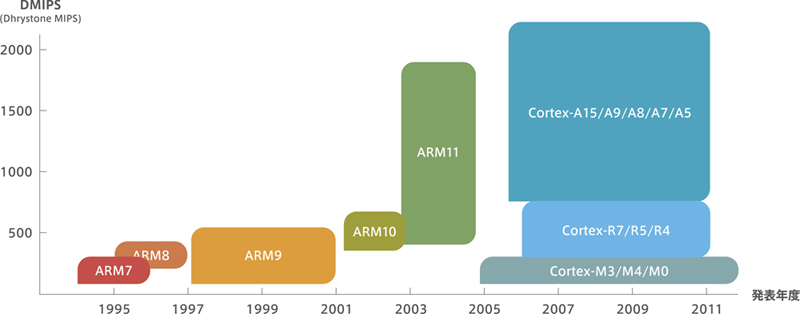
As mentioned on the previous page, the Arm processor started with the Arm1, but the product that can be said to be the de facto start is the Arm7.It’s still used all over the world today.Arm8, Arm9 and so on, while increasing the functionality from Arm7 The product has been rolled out.However, there are some products that have been popular and some that have not.For example, Arm8 was a revised and highly functional version of Arm7, butIt was replaced by Arm9, which came out next, and I’m told it was very short-lived.
Arm9 is still popular and widespread.That’s proof that Arm9 is as good as it gets.Below are some of the most popular products with Here are the characteristics of the core that are still used in the market today.

Cortex appeared
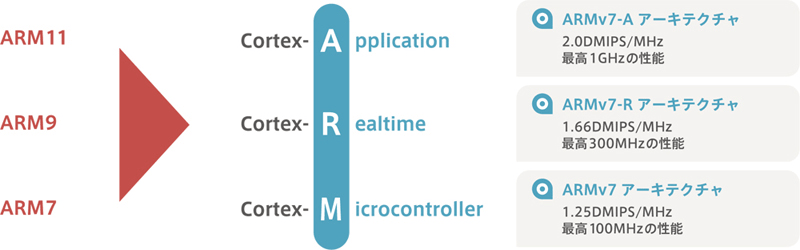
The next core in the Arm11 family will be the Cortex family, not the Arm12.Arm has grown rapidly in the mobile phone market, but now it is used in a wide range of applications beyond mobile phones (from high performance digital consumer electronics to industrial equipment), and the need to cover a wide range of performance and functionality has arisen.So, regardless of performance or functionality, we have unified the Cortex family and defined the architecture for each application. That’s Cortex-A, Cortex-R, and Cortex-M.
There are many products available for Cortex, but the main features of the typical products are listed below.

RISCとCISC
RISC
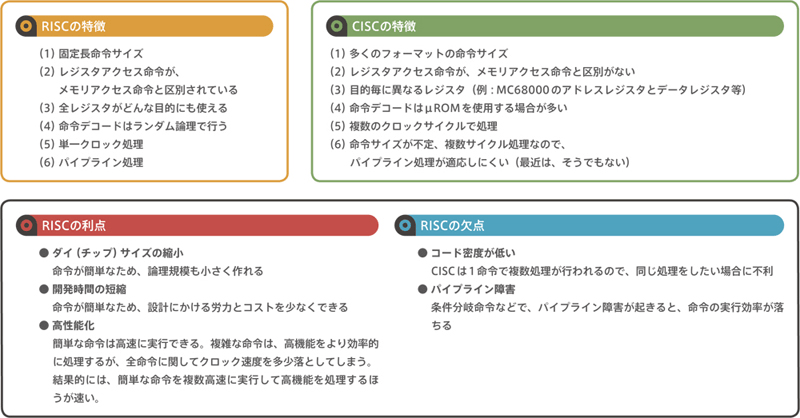
This is an acronym for Reduce Instruction Set Computer.
Although each instruction is simple to execute, it is the concept of efficiently executing a series of actions by combining them to make them fast.He was born around 1980 in a research program at Stanford University and the University of California, Berkeley.This is the architecture presented by Patterson and Ditzel. This was a surprise to those involved in microcomputers, because until then, the idea of using a single instruction to perform complex tasks to increase efficiency (CISC) had been the norm.
In order to minimize the execution time of a single instruction, we adopted the concept of a pipeline with a fixed length of instruction.Pipeline processing is a process that divides various processes into stages and performs partial parallel processing.On the face of it, one clock, one instruction execution can be achieved. However, in the case of conditional branching, etc., the pipeline is interrupted and a pipeline failure occurs, resulting in a loss of instruction execution efficiency.But Arm minimizes pipeline failures by incorporating branch speculation (prediction of branch destination) capabilities.
The concept of RISC has advantages not only for users but also for the developers of microcomputers.Since the instruction set is simple, single-clock-cycle execution, the internal logic is relatively easy to create. There is less work to develop microcomputers and the development time is shorter.This means that we can bring new products to market in a short period of time.
CISC
It is an acronym for Complex Instruction Set Computer.The concept is that a single instruction executes a series of complex operations to increase the overall execution efficiency of a microcontroller.The origin of microcomputers starts from the concept of CISC microcomputers.The format and execution time of each instruction varies from instruction to instruction. It has not been decided.Anyway, it’s one order and we’re going to do as much work as we can.
Compared to RISC, the instruction set is more complex, so it takes more time to develop a microcontroller.However, since there is a lot of work to be done with a single instruction, it has the advantage of accomplishing a lot of work with a small number of instructions, making ROM code more efficient.
RISC
In the text, I explained that “RISC is an architecture that was born around 1980 in a research program at Stanford University and the University of California, Berkeley, and published by Patterson and Ditzel.The RISC paper at this time was simplified and published in a scientific journal.And many microcomputer people have read it.
I was also a microcomputer designer at the time, so we all read this paper and discussed RISC together. The basic concept of RISC, “to execute simple instructions at high speed and combine them to execute a series of operations efficiently,” was an unprecedented idea, and most people were surprised.And I was half-heartedly skeptical if it was true. After all, at that point, there was no product to prove it…
However, the part about “adopting the concept of a pipeline with a fixed length of instruction” was questioned by most designers.This is because branching instructions, for example, depend on the result of the previous instruction, and the branch destination may change from the address that has been fetched beforehand.At this time, the pipeline process has to be re-fetched again.When such a pipeline failure occurs, the concept of one-clock, one-instruction execution cannot be adapted.Furthermore, the instructions themselves are simple to function, so they can produce very inefficient results.This was a major barrier, and the realization of RISC was thought to be difficult. (At least on my team.)
However, the RISC microcontroller was commercialized soon after the paper was published, and Arm also published a product that incorporated the RISC concept about five years after the RISC announcement.Then, in Arm11, we included a branching speculation (branching destination prediction) feature that minimizes the damage of pipeline failures, a drawback of RISC. The current Cortex has a branching speculation feature in all series. It still doesn’t completely eliminate pipeline failures, but it does improve the efficiency of instruction execution considerably.
Cortex
Cortex
Cortex is available in Cortex-A, Cortex-R and Cortex-M.A is an acronym for Application, R is Real time, and M is an acronym for Microcontroller.As you may have already noticed, when you put them side by side, you get Arm.The purpose of this article is to talk about Cortex-M in detail, so I won’t delve into Cortex-A and Cortex-R, but I will briefly explain them below.
Cortex-A
The architecture of Cortex-A will be Armv7-A. Typical series include the Cotex-A8 and others.At 2.0 DMIPS/MHz, it is the highest performance in Cortex and is designed to run at up to 1GHz, assuming a 180nm process.Recently, some 90nm process products have come out, so it will be possible to run even faster.The concept is an application processor for OS and user applications.
Cortex-R
The architecture of Cortex-R will be Armv7-R. Typical series include the Cotex-R4 and R4F.The processing power is 1.66DMIPS/MHz, which is a little inferior to Cortex-A, but it is still high enough.It is designed to operate at a maximum of 300MHz, assuming a 180nm process.The concept is an embedded processor for real time signal processing and control.
Cortex-M
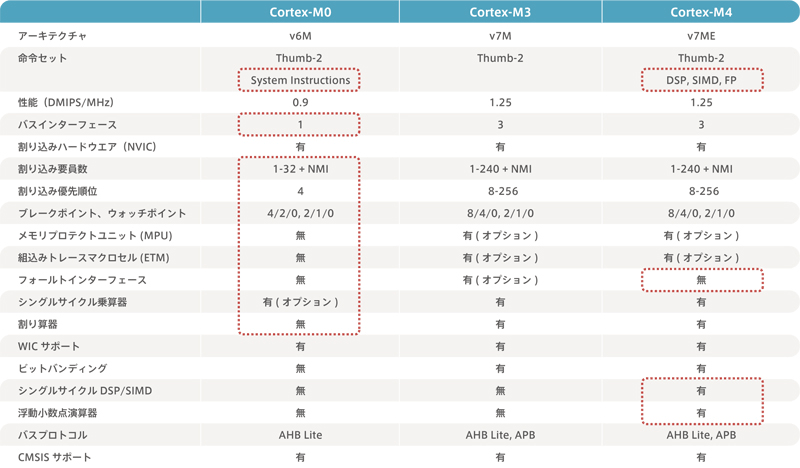
The architecture of Cortex-M will be Armv7-M. The series includes the Cotex-M0, M1, M3 and M4.The processing power is 0.9 DMIPS/MHz for Cortex-M0 and 1.25 DMIPS/MHz for Cortex-M3 and M4.Since the DMIPS benchmark does not have floating point operations, the M4 will be the same as the M3.It is inferior to Cortex-A and R, but it is high enough as a microcontroller.It is designed to operate at a maximum of 100MHz, assuming a 180nm process.However, there is already a 90nm process Cortex-M3 product, and a 120MHz / 150DMIPS product is on the market.The concept is a cost-conscious solution for microcontroller applications.
Features of the Cortex-M
The basis of Cortex-M is Cortex-M3. To this, DSP, SIMD, and FP functions/instructions are added to the Cortex-M4.In addition, from Cortex-M3, the instruction set has been reduced and the Cortex-M0 also removes the hardware division and bit banding functions.Cortex-M1 is a dedicated FPGA core.It is the same as Cortex-M0 in terms of function, but there is no general purpose product, so it is excluded this time.
The following are the basic features of Cortex-M3.
- Arm v7-M Architecture
- Thumb-2 instruction set architecture
- Provides both the performance of 32-bit code and the high code density of 16 bits
- Harvard architecture
- Instruction fetch and data access are executed in parallel by independent I&D bus
- Nested Vectored Interrupt Controller(NVIC)
- Low-overhead interrupt processing
- Vector table is not an instruction but an address
- Full C language support
- Reset, interrupt and exception handling are also available in C language
- integrated bus matrix
- bass arbiter
- bit banding
- Atomic bit operation is possible.
- write buffer
- Memory Interface (I&D) + System Interface & Dedicated Peripheral Bus
- Real-time operating system,Integrated system timer for scheduled tasks
- Three-stage pipeline: fetch, decode and execute
- single-cycle multiplication
- UDIV & SDIV (signed, unsigned division)
- Division takes 2 to 12 cycles depending on dividend and divisor
- If the dividend and divisor are about the same size, the division ends in fewer cycles
- Division can be interrupted (discard/restart)
Cortex-M processor
CPU core portability
Generally, the bit number of the CPU core is determined by the application function.For relatively low-functional applications, the 8/16-bit CPU core,16/32-bit CPU cores for medium-performance applications,For advanced applications, 32-bit or DSP is used. But in general, as the number of bits changes, so does the CPU core.In many cases, even if a single semiconductor manufacturer provides many CPUs, they are not compatible.
In order to prevent such problems from occurring in the Cortex-M series, M0, M3, and M4 are compatible at the binary level of the software and the development tools are also compatible in order to improve user usability.
Software Compatibility
There is software binary compatibility between the Cortex-M processors. This makes it easy to shift from M0 to M3 to M4.
The instruction set of the Cortex-Mx core is Cores with a large X number are fully upward compatible with smaller cores.Therefore, direct migration is possible.Increasing MCU clock speeds and moving from von Neumann to Harvard architecture makes it easy to improve performance.We recommend that you recompile your code if you want to move to a higher level product.
This is because the transition from Cortex-M0 to Cortex-M3, and from Cortex-M3 to Cortex-M4, allows for a more sophisticated instruction set. (Hardware varies, too.) M0 has only 56 instructions, and most of them are 16-bit long commands.These instructions are compatible with M3, so it is possible to migrate them at the binary level, but By recompiling, you can use many of M3’s 32-bit long-lived commands, making your code much more efficient.
When migrating from M3 to M4, recompilation enables the M4’s floating-point (FPU), DSP, and sum-of-product (SIMD) instructions to be used to achieve higher functionality.In the opposite case, the number of instructions is reduced in the transition from M4 to M3 and M3 to M0, so recompilation is required.

target application
The M0 is positioned to replace the 8/16-bit CPUs in low-end applications. The number of gates is almost the same as that of a 16-bit processor, so it is cost-optimized.
M3 is positioned to replace the 16/32-bit CPUs in middle applications. This is the image of an all-around player.
The M4 is positioned to replace the 32-bit/DSP in high-end applications.With FPU instructions, DSP instructions, sum-of-product instructions (SIMD), saturation instructions, etc., there is nothing to be afraid of.
Cortex-M0、M3、M4
Cortex-M0
I mentioned that the gate count is about the same as a 16-bit processor, but the performance is only 25-30% lower than the Cortex-M3.On the other hand, in terms of energy efficiency, it is superior to the M3.
The following are the main features.
- Only 56 instructions (except for 32-bit Thumb instructions BL, DMB, DSB, ISB, MRS, and MSR, all of which are 16-bit Thumb code)
- No hardware divider
- The execution time of the Load/Store instruction is 2 cycles
- Most MOV, add, subtract, compare, logic, and shift instructions are in one cycle
- Branch instructions are 1 to 4 cycles (depending on conditions and links)
- 32 bits x 32 bits multiplication, result is 32 bits: 1 cycle
- Breakpoint/Watchpoint Reduction (4/2)
- Only Serial-Wire-Debug (SWD) is supported. (No JTAG circuit)
- Privilege levels are unsupported.
- no bit-banding
- Unaligned data is not available.
Cortex-M3
The features have already been described in the “Cortex” chapter above.
Cortex-M4
The following features have been added to M3
- DSP and SIMD Extended Instruction Set
- Single-cycle MAC operations (32 x 32 + 64 → 64)
- 16-bit MAC (dual 16-bit MAC) → 4 times the performance of M3
- 32-bit MAC → Twice as high performance as M3
- Up to 64-bit MAC → 7 times higher performance than M3
- Single precision floating point unit (FPU) (option)
- With power down function
- saturation operation
- Minimum and maximum value clipping prevents variable overflow and reduces CPU load due to software range checking.In audio and control applications, the integral term of the PID controller is computed continuously over time.The saturation operation automatically limits the variable values and reduces the number of CPU cycles per regulator.
Arm7 to Cortex-M3
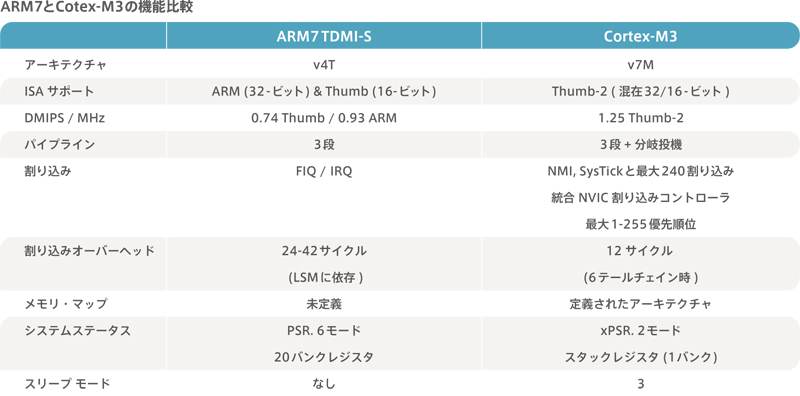
Comparison of Arm7 and Cortex-M3
The successor series to the Arm7 will be the Cortex-M3.
What improvements has Cortex-M3 made from Arm7?
The table below summarizes the comparison between Arm7 and Cortex-M3.
instruction set
The Arm instruction (32 bits long) and the Thumb instruction (16 bits long) have been unified into the Thumb-2 instruction (16 bits long, mixed 32 bits long).
Improved computing power
The DMIPS/MHz comparison improves from 0.74 (with Thumb instructions) / 0.93 (with Arm instructions) to 1.25. A DMIPS/MHz of 1.0 or higher means that the operation is more efficient than one clock and one instruction.
pipeline
The number of steps remains the same at 3, but a branch speculation function has been added.
interruption
The exception handling that was handled by the assembler in Arm7 is now handled by the hardware in Cortex-M3.Therefore, the overhead of interrupt processing is shortened. It is also possible to write interrupt processing without using assembler code (C language).
memory map
The address allocation of the memory is fixed.This is because it is not possible to change the position of the alias and the original when performing bit-band processing.The details of the bit bands are explained separately.
Reduced debugging pins
Trace interface pins have been reduced from 9 to 2-3 pins, increasing the number of pins that can be used for general purpose IO pins.Thus, the pin overhead has been reduced.
Atomic bit manipulation (bit banding)
Additional functions have been added to make bit manipulation easier.Thus, bit-by-bit access is improved.
Built-in sleep control and power-down mode
The CPU’s unique low power consumption mode has been newly added.When the microcontroller is in the low power consumption mode, the CPU also enters the low power consumption mode.
option
An optional Small Range Memory Protection Unit (MPU) to facilitate memory management and an embedded trace macrocell (ETM) to enable instruction tracing are provided.Even though it is an option, it is not chosen by the user, but by the microcomputer vendor who has received the license of IP and incorporates it into the product.

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …