





Overview and Features
Supercalar Pipeline Basics
The process of a superscalar pipeline can be broadly divided into the first half of the process from instruction fetching to instruction decoding (Decode) and instruction issuance (Issue), and the second half of instruction execution. The first half is called the instruction issuance pipeline and the second half is called the instruction execution pipeline.
The number of instructions that can be sent from the instruction decoder (Decode) to the instruction execution pipeline at the same time is called an Issue, and the number of instruction execution pipelines is called a Way, and in the case of the Cortex-M7, both are two (dual issue, dual way).
Cortex-M7 pipeline
The Cortex-M7 pipeline is processed in 64 bits. This means that two 32-bit instructions are processed at the same time.
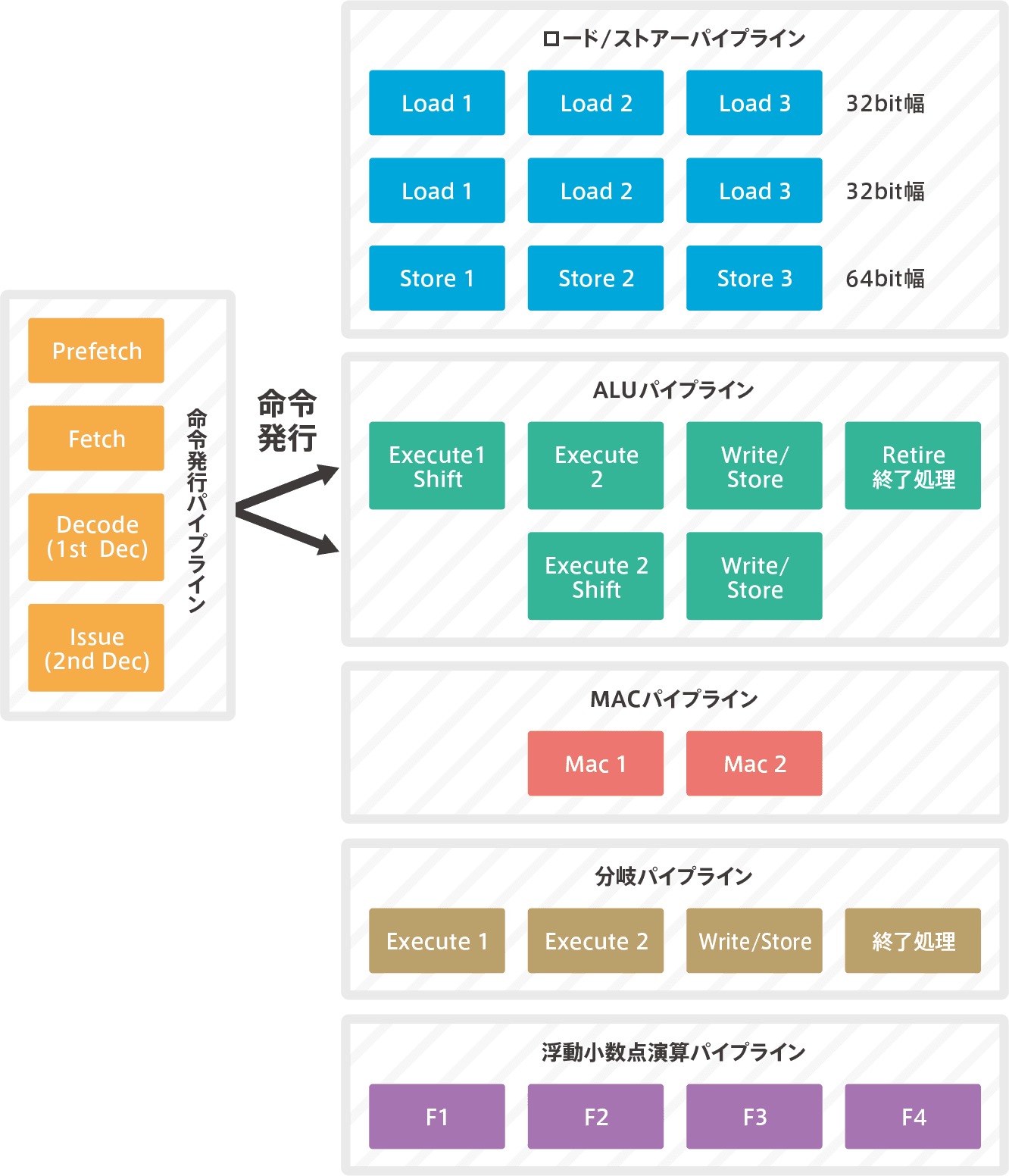
【Cortex-M7のパイプライン】
It is a pipeline through which all instructions pass until the first half of the instruction is issued. It is a pipeline process from prefetching to decoding and discriminating instructions.The decoding process is in two stages, the first decode is called Decode and the second decode is called Issue. After the issuance, the two orders are passed on to the second half.
The later execution pipelines are divided into multiple execution pipelines depending on the type of instruction.The load/store instruction goes through the load/store pipeline; the ALU operation instruction goes through the ALU pipeline.Since two ALU pipelines are matched and can be operated at the same time, it has a dual super-scalar pipeline structure.The shifter is included here. Complex sum-of-product operations run through the MAC pipeline. Floating-point arithmetic is computed in the floating-point arithmetic pipeline.
Since the Cortex-M7 superscalar is issued in-order, the instructions are basically executed in the order of the program.Almost all instructions are completed in the order of the program, but floating-point operations are completed in no order (called out-of-order).Also, since it is dual-issue, most of the pair of instructions can be executed at the same time.
In-order and out-of-order issuance
Normally, instructions are executed in the order in which they were issued, but if instructions with different execution clocks are issued at the same time, the order of completion of execution may be swapped.The method where the processing is in the order of the program is called in-order issuance, and the method where the processing is different from the order of the program is called out-of-order issuance.Out-of-order issuance is definitely better performance, but the hardware for managing and controlling instruction execution is more complex.In-order issuance is easy on the hardware, but poor on the performance.
Order Issuance and Restrictions

Micro-manipulation (μ-Op)
The term “micro-manipulation” comes to mind when studying super-scara. Since SuperScalar executes instructions by “micro-manipulation”, let’s first explain “micro-manipulation”.
Since RISC microcomputers did not handle complex instructions in the first place, the internal logic circuitry of Decode has been composed of random logic or wired logic.Micro-instructions and micro-programs have not been used in CISC, where a single instruction is executed by more detailed micro-manipulation.
However, in recent years, RISC microcomputers have come to handle complex instructions such as CISC microcomputers, and it has become necessary to process complex instructions.Attempting to process complex instructions in random or wired logic makes the internal logic structure more complex and reduces circuit efficiency. Therefore, RISC microcomputers that use the superscalar method have come to use the micro-operation method.
In this method, the decoded instructions are further divided into a number of micro-operations. This micro-manipulation is called μ-Op.
Decode
Instructions decoded with Decode are checked here in preparation for instruction issuance. It then decomposes the decoded instructions into micro-operations (μ-Op). Then it is handed over to the next stage, Issue.
Publication Stage (Issue)
The data dependency state is determined by μ-Op before entering the execution pipeline. In other words, it checks if it can be issued at the same time.If there is no dependency between the two instructions at all, or if either ALU is executable, they are issued and executed concurrently.
If you draw an image, it will look like the following (a).
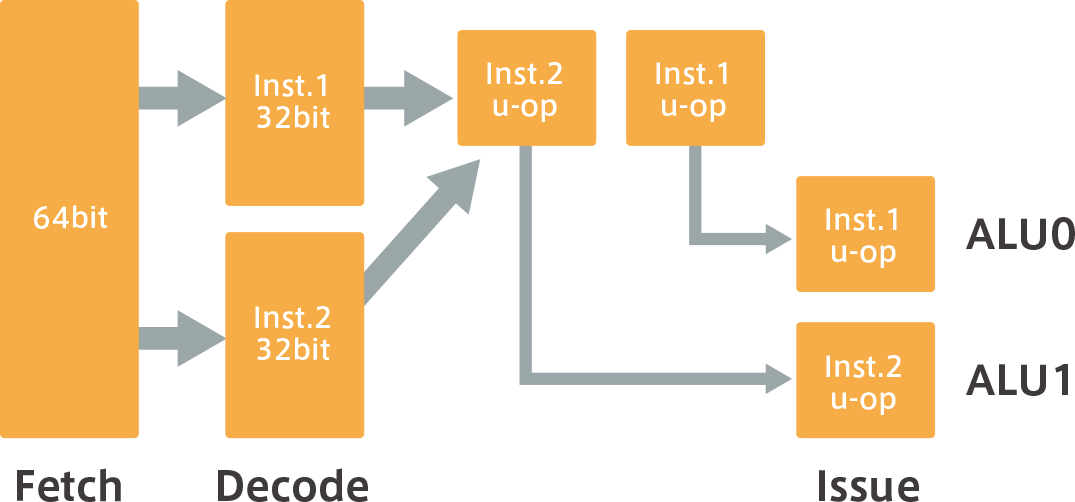
(a) There is no dependency between Inst.1 and Inst.2, and it is possible to issue and execute at the same time.
However, if two instructions cannot be issued at the same time, or can only be executed by one ALU, then one of the instructions will be interlocked because it cannot be issued at the same time.In other words, μ-Op is temporarily stopped and executed in the next cycle, as shown in (b) below.For example, a SIMD (Single Instruction Multiple Data) instruction can only be operated by one ALU, so it cannot be issued at the same time, and one of the instructions will be interlocked.
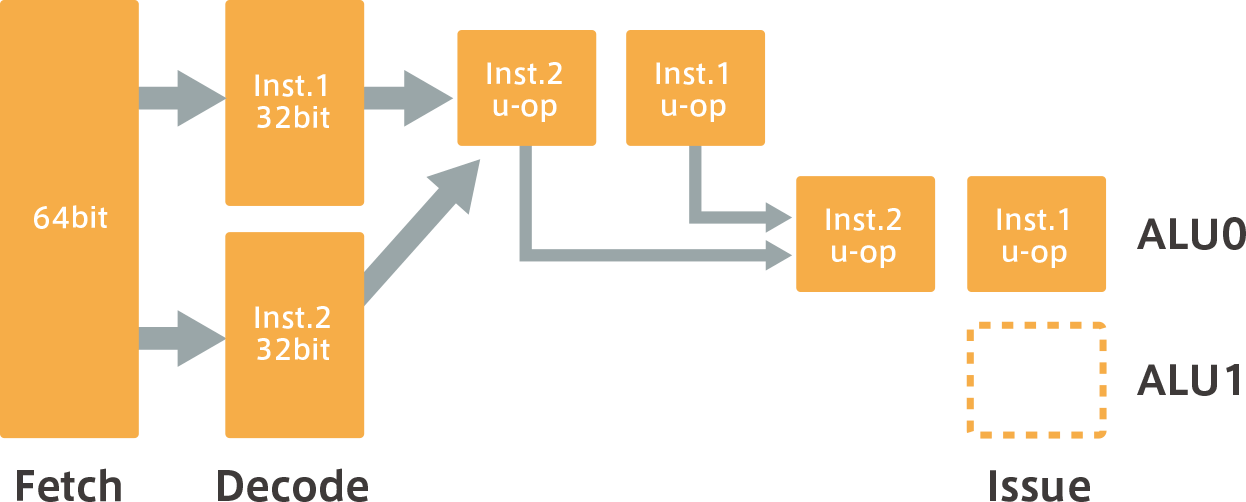
(b) When Inst.1 and Inst.2 are dependent on each other and cannot be issued or executed at the same time
Dual issuance restrictions
issue limit
Some instructions will not be dual-issued. It is not disclosed which instructions will not be dual-issued, so it cannot be stated, but the structure of the super-scalar pipeline leads us to believe the following
For example, unaligned loads (when crossing a 32-bit boundary) and unaligned stores (when crossing a 64-bit boundary) are not dual-issued because they are internally converted and executed into two or more aligned accesses, as described in the chapter “Handling Unaligned Accesses in Boundaries (see Part 2)”.A SIMD instruction can only be operated by one ALU, so it will not be issued dual.
The floating-point arithmetic pipeline is only one way, so dual integer and floating-point division float splits, floating-point square root, and double-precision floating-point instructions are not issued.However, it can be executed in parallel with the integer pipeline. (The actual floating minority point arithmetic pipeline is divided into two parallel pipelines, but one is a simple arithmetic pipeline for addition, etc., and the other is an arithmetic pipeline for multiplication, division, etc., so it is effectively a single way.Details will be discussed in the chapter “Execution Pipeline (see Part 5)” below.
Also, non-generic instructions are generally not dual-issued.For example, a mode transition instruction or an instruction used during debugging is not dual-issued because the next instruction that follows must be executed in a different mode or condition.In Cortex-M7, the SVC (Supervisor Call) instruction, which shifts to privileged mode, the BKPT (Break Point) instruction, which is used for debugging, and the MRS, MSR, DMB (Data Memory Barrier), and DSB (Data Synchronization Barrier) instructions, which handle special registers such as PRIMASK, also change the state of the memory, so these instructions are non-general-purpose instructions.
To summarize, no dual issuance will be performed on the following instructions
- Unaligned loading (when crossing a 32bit boundary)
- Unaligned store (when crossing 64bit boundaries)
- Integer and floating-point division float division
- floating-point square root
- All double-precision floating-point instructions
- Non-General Purpose Instructions – SVC, BKPT, MRS, MSR, DMB, DSB
In the case of superscara, there is an issue limit attached. Fewer issue limits mean more computing efficiency and better performance.To do so, the compiler will come up with an instruction array so that it can be issued as little as possible.
Since the Cortex-M series is compatible at the object level from M0 to M7, the results compiled with the lower Cortex can be executed as is with the upper Cortex. However, the best performance will not be obtained unless the appropriate compiler is used for each Cortex.
Cortex-M0/M0+ → M3 → M4 increases the number of instructions, so it is obvious that recompilation is valid, but the difference between Cortex-M4 and Cortex-M7 is only double precision floating minority instructions.However, from the perspective of issue limits, Coretx-M7 will get better performance if you use a corresponding compiler to obtain objects with the issue limit minimized.
For example, the latest compiler (as of November 14, 2015) of μVision, a genuine Arm tool, generates superscalar-aware optimization code by specifying “--cpu=Cortex-M7” as the compile option.

“もっと見る” カテゴリーなし

Mbed TLS overview and features
In this article, I'd like to discuss Mbed TLS, which I've touched on a few times in the past, Transport …
What is an “IoT device development platform”?
I started using Mbed because I wanted a microcontroller board that could connect natively to the Internet. At that time, …
Mbed OS overview and features
In this article, I would like to write about one of the components of Arm Mbed, and probably the most …